

Gestionar trabajos de PSI sin contar repeticiones/100% [PMM]
1. Introducción
El presente caso práctico solamente afecta en caso de que el cliente PSI pida no revisar/no contabilizar las repeticiones (o las repeticiones y 100% fuzzies). Este proceso implica un coste adicional de preparación de archivos para el cliente; consultar el apartado correspondiente del manual de PSI.
El cliente PSI envía varios archivos para traducir, que pueden ser en PDF o en Word (el proceso a seguir en un caso o el otro variará ligeramente). Para explicar las distintas posibilidades, usaremos como ejemplo un proyecto con originales en PDF, es decir, para el que necesitamos preparar un presupuesto basado en un OCR sin arreglar.
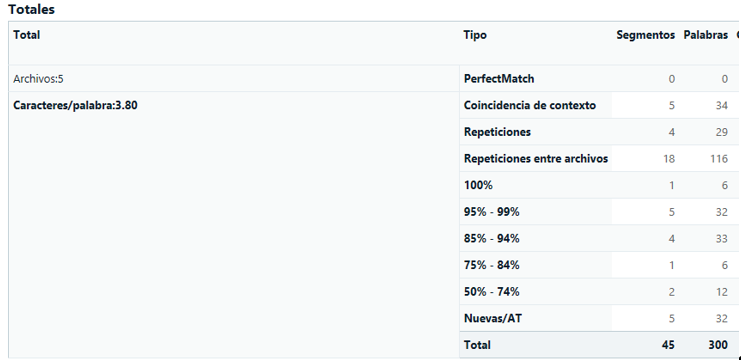
En este ejemplo se han utilizado 5 archivos de prueba, se han analizado los OCR con la TM del cliente, y obtenemos el siguiente log:
2. Primera posibilidad: No recuento de repeticiones
ATENCIÓN: como veremos a continuación, si los originales son en PDF, se pueden analizar los OCR de manera habitual de cara al presupuesto (los pasos especiales son para la preparación de los archivos editados), pero si los originales son en Word, ya habrá que analizarlos y prepararlos de manera especial para la fase del presupuesto.
El cliente nos pide que NO contabilicemos las repeticiones para su presupuesto, por lo que habría que dejar a cero el coste de esas 179 palabras (resultantes de “Coincidencia de contexto: 34”, Repeticiones: 29” y “Repeticiones entre archivos: 116”), de manera que en el presupuesto sea visible la cantidad de palabras que necesitamos bloquear cuando tengamos lista la edición de los PDF, o lo que es lo mismo, que existen 179 repeticiones pero que no contabilizaremos y, por lo tanto, no las traduciremos/revisaremos.
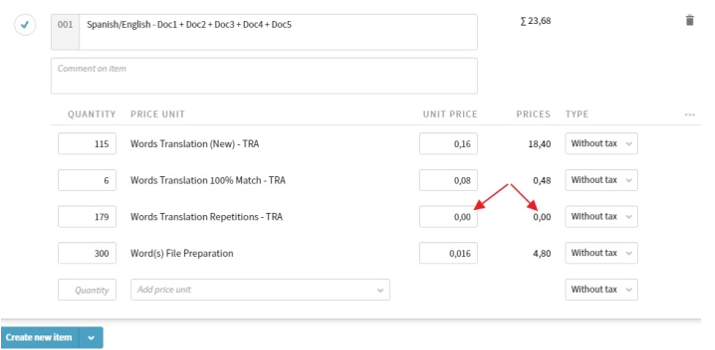
Así las pondremos a 0€ en Plunet:
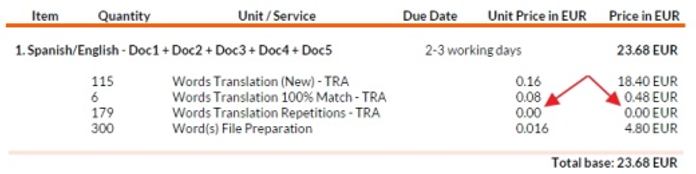
Y así se verán a 0€ en el presupuesto creado:
Más adelante veremos el proceso que conviene seguir. De momento, imaginemos que analizamos los archivos como solemos hacer, con la TM del cliente y enviamos el presupuesto. Cuando tenemos la confirmación, procedemos a arreglar el OCR de los archivos y, cuando los tenemos listos, realizamos un nuevo análisis con la TM del cliente, que resulta así:
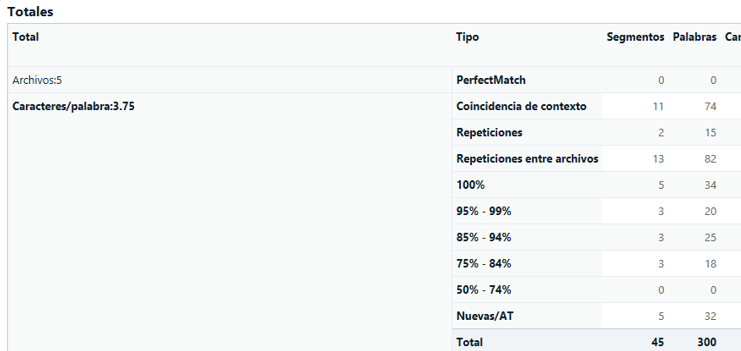
Como vemos, al arreglar los OCR ya no obtenemos el mismo log, e incluso ha habido un cambio en el número de repeticiones y 100% matches (entre otros).
Antes veíamos 179 repeticiones (34+29+116) y 6 palabras al 100%, mientras que ahora vemos 171 repeticiones (74+15+82) y 34 palabras al 100%.
Sin embargo, nosotros al cliente le hemos descontado 179 palabras, no 171, y además en este caso lo único que no revisaremos son las repeticiones, pero sí tenemos que revisar las 100%.
El motivo por el que ocurre esto es que Trados da preferencia a la TM, por lo que si un segmento lo encuentra en la TM y ya está traducido, lo asigna a un % fuzzy antes que a una repetición.
Puesto que en la TM solo tenemos textos que hemos traducido (y que previamente han sido arreglados tras OCR), cuando hacemos el primer análisis del OCR sin arreglar puede haber segmentos que, debido a que están sin arreglar, no aparezcan en la TM. Sin embargo, al repetirse en el proyecto actual, aparecen como repeticiones.
Para evitar esta cuestión, este será el proceso de preparación del proyecto cuando tengamos que bloquear repeticiones (solo):
ORIGINALES EN PDF
- 1) Para el presupuesto, analizamos los OCR como de costumbre, con la TM del cliente, y el log que obtenemos es el que usaremos para el presupuesto (poniendo las repeticiones a cero).
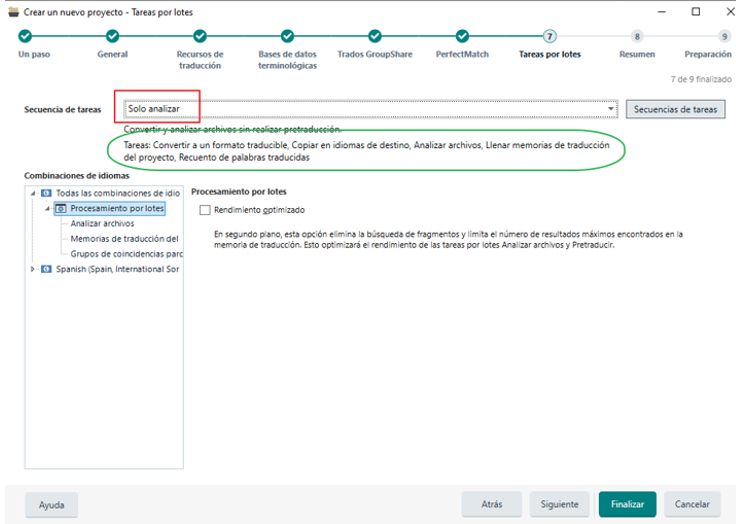
- 2) Tras el OK del cliente y ya con los archivos editados, los analizamos de nuevo con la TM de cliente, pero con la Secuencia de tareas “Solo analizar”, que se muestra en el paso 7 Tareas por lotes, del asistente de Trados. (En el marco verde de la imagen inferior se muestra las tareas que hace Trados con dicha secuencia de tareas).
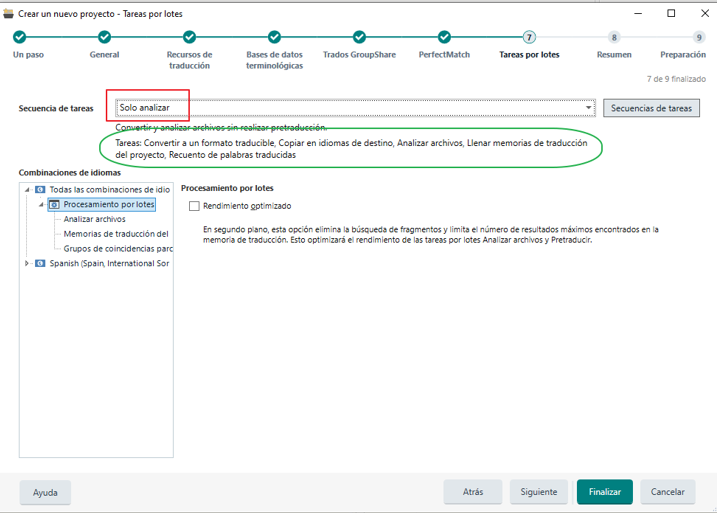
Esta secuencia de tareas nos permitirá añadir la TM del cliente, pero Trados NO la usará para pretraducir los archivos. De este modo, nos aseguramos de bloquear las repeticiones al cliente, sin que haya nada pretraducido. Además, con esta secuencia de tareas Trados también nos crea una memoria de traducción de proyecto en local (que se guardará en la carpeta con el resto de archivos del proyecto en tu ordenador) y que posteriormente podremos usar para pretraducir las repeticiones tal y como se explica más adelante en el paso 6.
- 3) Ahora, abriríamos todos los archivos (si son varios, se recomienda abrirlos todos a la vez). Para ello los seleccionaríamos todos y haríamos click en “Abrir para traducción”:
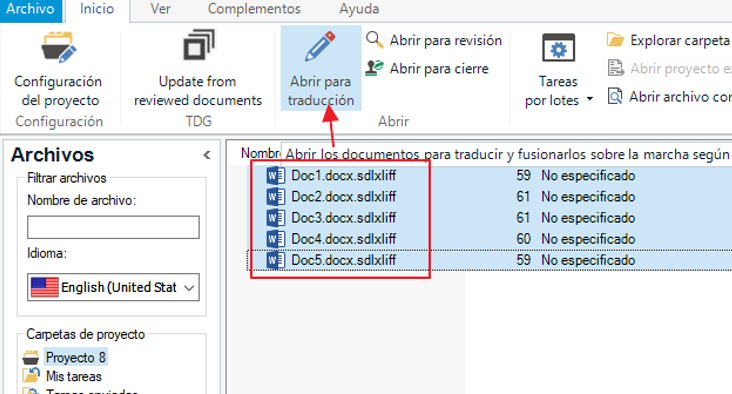
Procedemos a aislar esas repeticiones y bloquearlas, de acuerdo con el paso Paso anterior a traducir (preparación) del artículo Crear sdlxliff con repeticiones bloqueadas para que no se revisen
- 4) Una vez tenemos los sdlxliff con las repeticiones bloqueadas, vamos a “Tareas por lotes”, seleccionamos “Pretraducir archivos”.
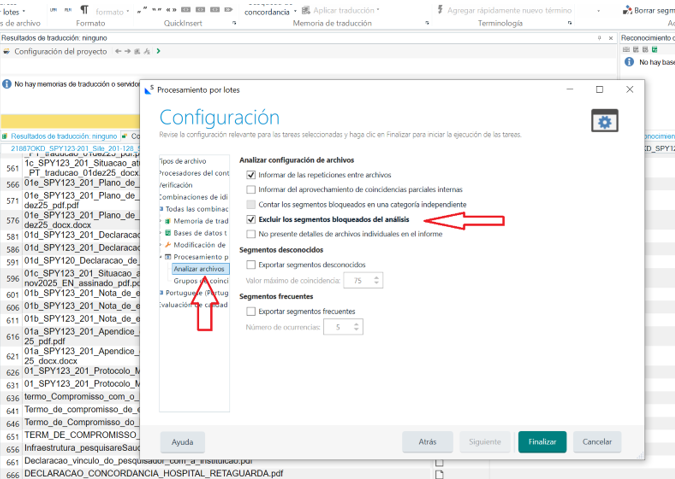
- 5) Hecho el paso previo, hacemos otra «Tareas por lotes» seleccionando «Analizar archivos». En las opciones elegiremos la opción “Excluir segmentos bloqueados del análisis”.
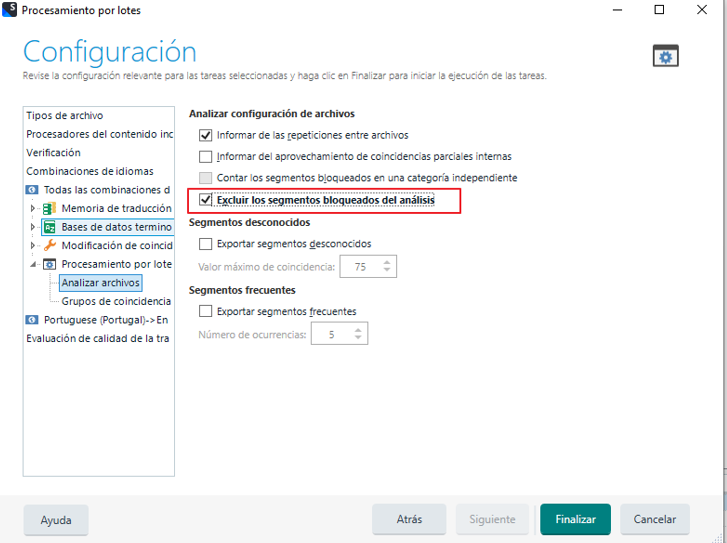
Nota: Los pasos 4 y 5 pueden simplificarse con una Tarea por lotes personalizada, donde añadamos, en este orden, Pretraducir archivos y Analizar archivos (recordando marcar la opción de “Excluir los segmentos bloqueados del análisis” antes de Finalizar):
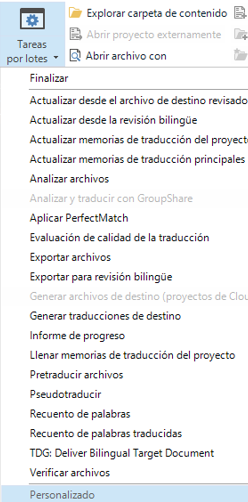
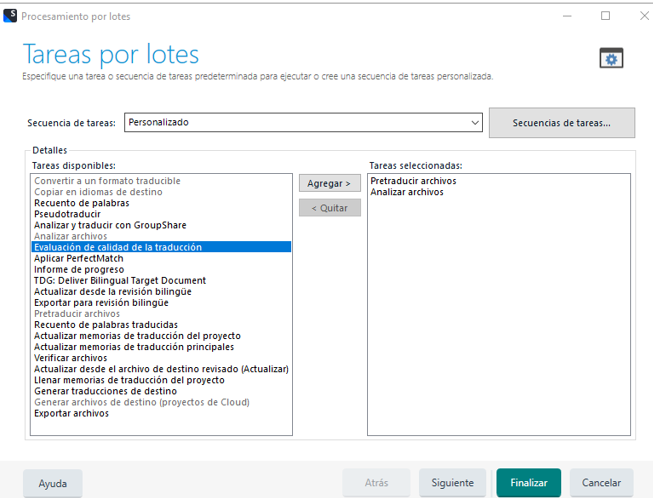
Volviendo al ejemplo inicial, este sería el resultado:
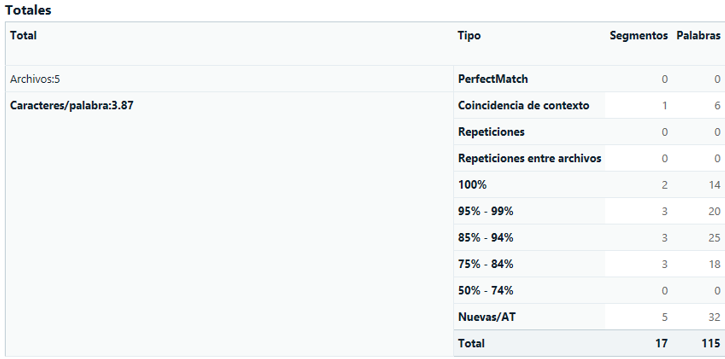
Este será el log (y los SDLXLIFF) que usaremos para enviar a traducir.
- 6) Una vez el trabajo se ha traducido (o traducido y revisado y realizado el QA correspondiente), debemos generar las repeticiones que habíamos bloqueado anteriormente. Para ello, realizaríamos el Paso posterior a traducir del artículo Crear sdlxliff con repeticiones bloqueadas para que no se revisen
Al tratarse de varios documentos, nuevamente se recomienda abrirlos todos a la vez.
Nota: En el caso de que haya varios archivos, se recomienda crear una TM de trabajo vacía en local y guardada en nuestro ordenador e importar en ella estas traducciones. Ver Crear sdlxliff con repeticiones bloqueadas para que no se revisen. No obstante, como se comentaba en el punto 2, al crear el proyecto Trados ya nos ha creado una memoria de traducción en local guardada en nuestro ordenador, por lo que podremos usar esa misma memoria para importar las traducciones.
ORIGINALES EN WORD
Con originales en Word (no OCR), saltaremos directamente al 2) para analizar los archivos para el presupuesto.
- 2)Analizamos los archivos con la TM del cliente, pero con la Secuencia de tareas “Solo analizar”, que se muestra en el paso 7 Tareas por lotes, del asistente de Trados. (En el marco verde de la imagen inferior se muestra las tareas que hace Trados con dicha secuencia de tareas).
- 3) Ahora, abriríamos todos los archivos (si son varios, se recomienda abrirlos todos a la vez). Para ello los seleccionaríamos todos y haríamos click en “Abrir para traducción”:
Procedemos a aislar esas repeticiones y bloquearlas, de acuerdo con el paso Paso anterior a traducir (preparación) del artículo Crear sdlxliff con repeticiones bloqueadas para que no se revisen
- 4) Una vez tenemos los sdlxliff con las repeticiones bloqueadas, vamos a “Tareas por lotes”, seleccionamos “Pretraducir archivos”.
- 5) Hecho el paso previo, hacemos otra “Tareas por lotes” seleccionando “Analizar archivos”. En el caso de originales con Word es importante escoger “Contar los segmentos bloqueados en una categoría independiente” (en lugar de “Excluir”):
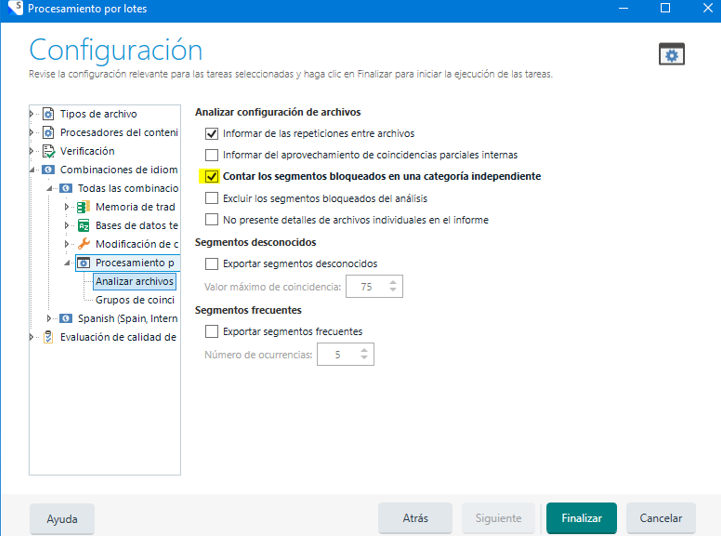
De este modo, en el análisis sí saldrán las repeticiones, pero en una categoría independiente. Ejemplo:
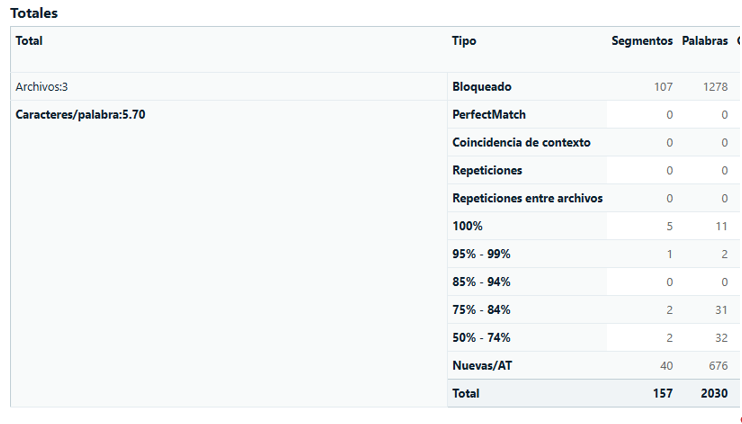
Nota: Los pasos 4 y 5 pueden simplificarse con una Tarea por lotes personalizada, donde añadamos, en este orden, Pretraducir archivos y Analizar archivos (recordando marcar la opción de “Contar los segmentos bloqueados en una categoría independiente” antes de Finalizar):
- Este recuento y estos SDLXLIFFs son los que nos servirán tanto para el presupuesto como para sacar el trabajo a traducir cuando tengamos el OK del cliente. Cuando carguemos este report en Plunet, recordemos poner las repeticiones a cero, tanto para el cliente como para el traductor.
- 6) Una vez el trabajo se ha traducido (o traducido y revisado y realizado el QA correspondiente), debemos generar las repeticiones que habíamos bloqueado anteriormente. Para ello, realizaríamos el Paso posterior a traducir del artículo Crear sdlxliff con repeticiones bloqueadas para que no se revisen
Al tratarse de varios documentos, nuevamente se recomienda abrirlos todos a la vez.
Nota: En el caso de que haya varios archivos, se recomienda crear una TM de trabajo vacía en local y guardada en nuestro ordenador e importar en ella estas traducciones. Ver Crear sdlxliff con repeticiones bloqueadas para que no se revisen. No obstante, en el punto 2, al crear el proyecto Trados ya nos ha creado una memoria de traducción en local guardada en nuestro ordenador, por lo que podremos usar esa misma memoria para importar las traducciones.
3. Segunda posibilidad: No recuento de repeticiones ni 100% fuzzies
ATENCIÓN: como veremos a continuación, si los originales son en PDF, se pueden analizar los OCR de manera habitual de cara al presupuesto (los pasos especiales son para la preparación de los archivos editados), pero si los originales son en Word, ya habrá que analizarlos y prepararlos de manera especial para la fase del presupuesto.
El cliente nos pide que NO contabilicemos las repeticiones NI los fuzzies 100% para su presupuesto, por lo que habría que dejar a cero el coste de esas 185 palabras (resultantes de “Coincidencia de contexto”, “Repeticiones”, “Repeticiones entre archivos” y “100%”), de manera que en el presupuesto sea visible la cantidad de palabras que necesitamos bloquear cuando tengamos lista la edición de los PDF, o lo que es lo mismo, que existen 185 palabras pero que no contabilizaremos y, por lo tanto, no las traduciremos/revisaremos.
Así las pondremos a 0€ en Plunet:
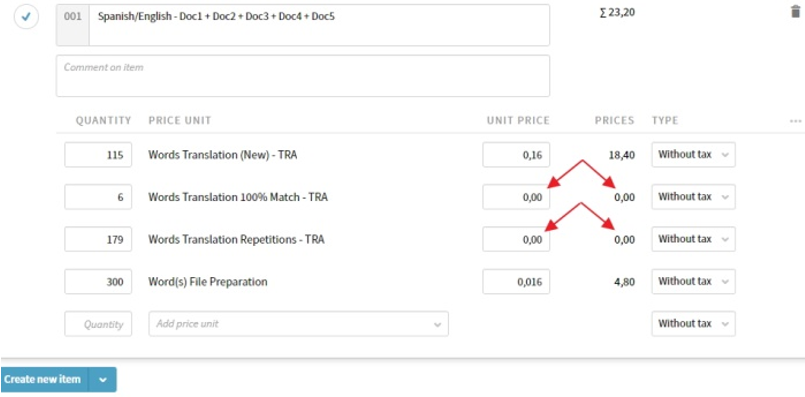
Así se verán a 0€ en el presupuesto creado:

Más adelante veremos el proceso que conviene seguir. De momento, imaginemos que analizamos los archivos como solemos hacer, con la TM del cliente y enviamos el presupuesto. Cuando tenemos la confirmación, procedemos a arreglar el OCR de los archivos y, cuando los tenemos listos, realizamos un nuevo análisis con la TM del cliente, que resulta así:
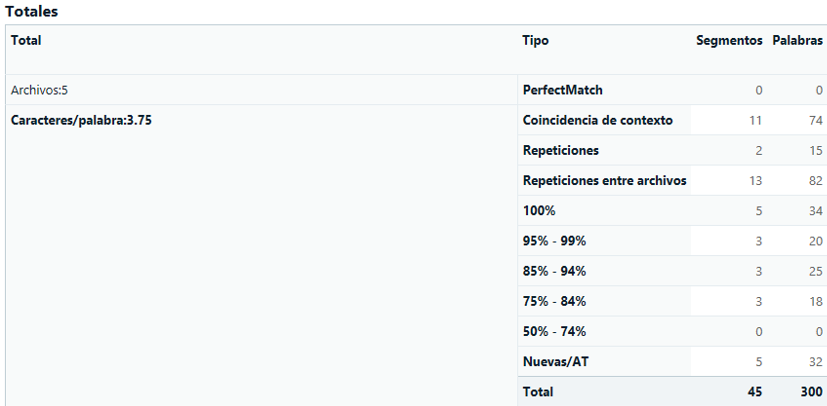
Como vemos, al arreglar los OCR ya no obtenemos el mismo log, e incluso ha habido cambios en los diferentes rangos. A priori, todos los cambios serán, en general, para nuestro beneficio, así que no nos preocuparemos demasiado por ello.
El proceso de preparación del proyecto cuando tengamos que bloquear tanto repeticiones como 100% matches es el siguiente. Será prácticamente el mismo con originales tanto en PDF como en Word:
- 1) Para el presupuesto, si los originales son en Word, saltamos directamente al punto 2) para preparar ya los documentos correctamente para el presupuesto. Si los originales son en PDF, analizamos los OCR como de costumbre, con la TM del cliente, y el log que obtenemos es el que usaremos para el presupuesto (poniendo repeticiones y 100% matches a cero).
- 2) Tras el OK del cliente y ya con los archivos editados (o con originales en Word), los analizamos de nuevo con la TM del cliente (con la Secuencia de tareas habitual, no hay que hacer nada especial).
- 3) Procedemos a aislar esas repeticiones y palabras 100% y bloquearlas, de acuerdo con el paso Paso anterior a traducir (preparación) del artículo Crear sdlxliff con repeticiones bloqueadas para que no se revise aunque en este caso filtraremos por “Traducido” y por “Excluir primeras ocurrencias”, bloqueando cada vez lo que resulte de cada filtro.
Cuando tenemos todo lo que necesitamos debidamente bloqueado en los SDLXLIFF, guardaremos, vamos a “Tareas por lotes”, seleccionamos “Analizar archivos” eligiendo la opción “Excluir segmentos bloqueados del análisis”.
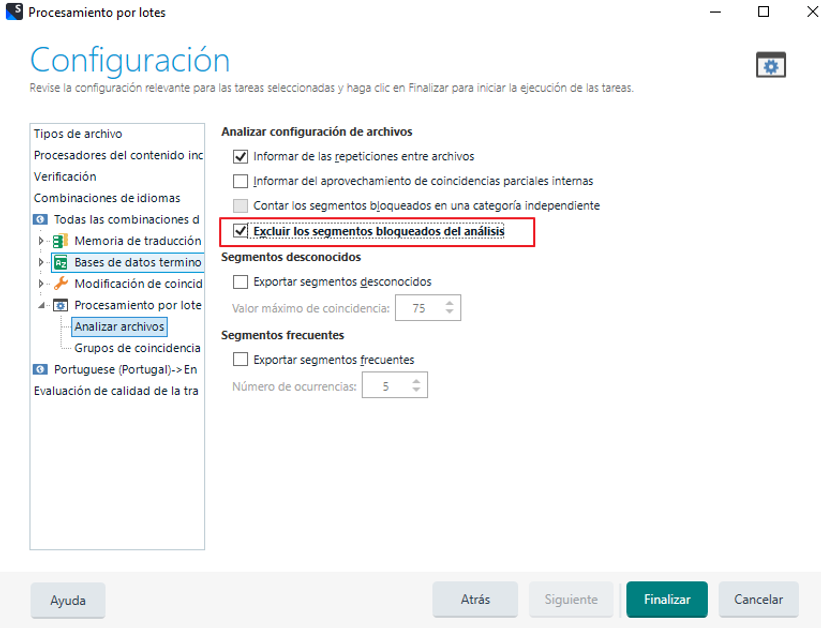
Ese será el log (y los SDLXLIFF) que usaremos para enviar a traducir (en el caso de originales en Word, para el propio presupuesto también).
- 5) Una vez el trabajo se ha traducido (o traducido y revisado y realizado el QA correspondiente), debemos generar las repeticiones que habíamos bloqueado anteriormente (los 100%, sin embargo, ya estarán traducidos). Para ello, realizaríamos el Paso posterior a traducir del artículo Crear sdlxliff con repeticiones bloqueadas para que no se revise
Al tratarse de varios documentos, nuevamente se recomienda abrirlos todos a la vez.
En el caso de que haya varios archivos, se recomienda crear una TM de trabajo vacía en local y guardada en nuestro ordenador e importar en ella estas traducciones. Ver Crear sdlxliff con repeticiones bloqueadas para que no se revise.
4. Finalización
Llegados a este punto, con los segmentos que teníamos bloqueados ya desbloqueados, realizamos la pretraducción, con la siguiente configuración:
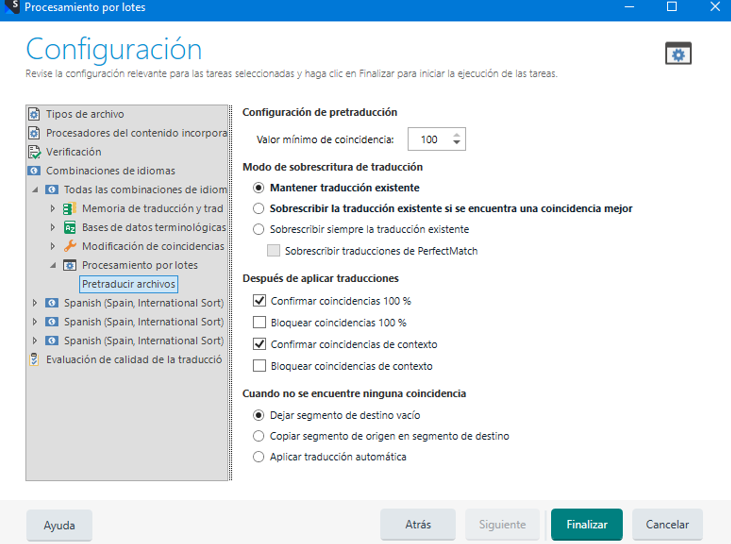
De este modo, ya tendremos todo traducido y con ello podremos generar los archivos de destino:

A menudo, los archivos no se muestran traducidos al 100%. Habría que abrirlos para traducción todos a la vez (tal y como se ha explicado más arriba) y usar los filtros de Trados para filtrar esos segmentos que se han quedado sin confirmar:
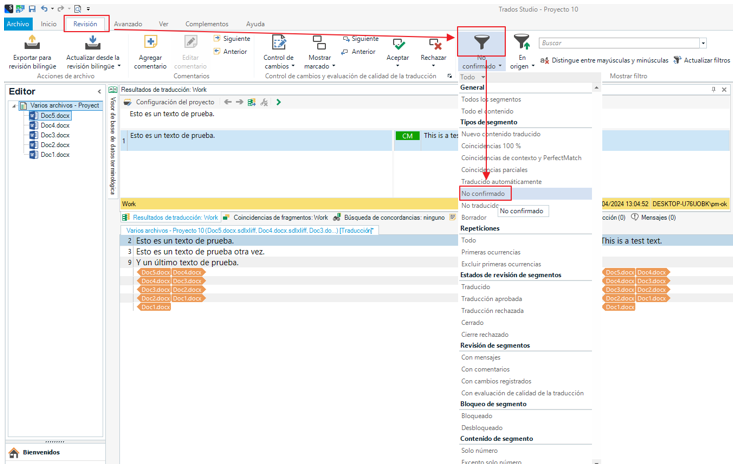
Cuando los tengamos filtrados, habría que ponerse encima de cada segmento vacío y automáticamente la memoria de traducción ya encontrará la coincidencia, o la PM tendrá que corregir el contenido como corresponda para que coincida con el segmento original. Una vez revisados/corregidos todos los segmentos pretraducidos, confirmamos esos segmentos, guardamos los SDLXLIFF finales y generamos los archivos de destino, siempre que previamente ya hayamos realizado el control de calidad.
6. Paso a paso para excluir repeticiones y 100% matches en archivos con filenames
Nota previa: Las repeticiones y los 100% matches se podrán excluir de todo el archivo salvo de los filenames, los cuales se considerarán todos como New words y se contabilizarán como se explica aquí.
Presupuesto
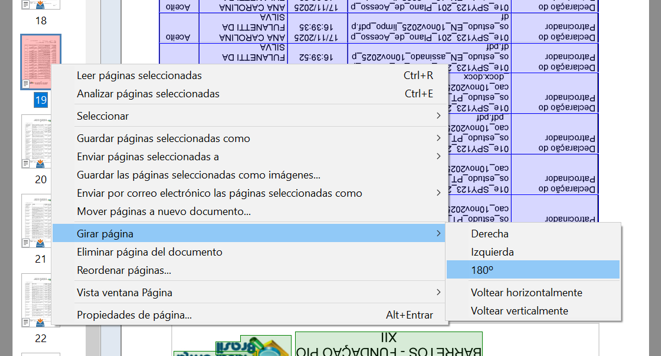
Pasamos el archivo por Abbyy normalmente. Siempre es importante revisar que todas las páginas se lean correctamente, porque hay páginas completas que pueden aparecer volteadas. En ese caso, hay que hacer click con botón derecho, girarlas 180º desde Abbyy y volver a “leerlas” antes de generar el nuevo Word sucio.
Una vez que tengamos todas las páginas leídas correctamente, generamos el nuevo Word, y vamos a la parte donde comienzan los filenames. Nos paramos sobre la columna de los filenames y nos va a aparecer una flechita negra, hacemos click y se selecciona toda la columna.
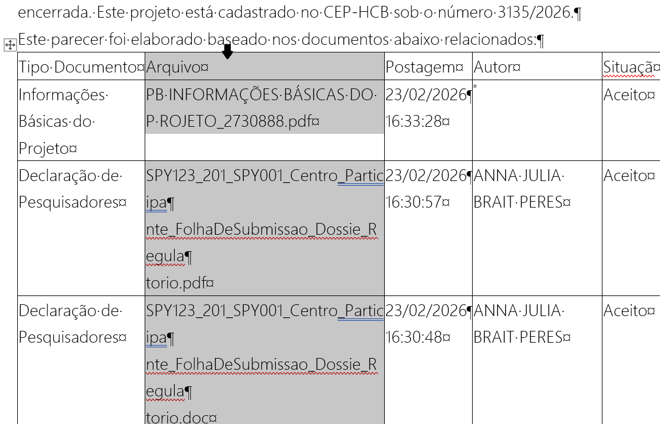
Una vez que la tenemos seleccionada, la cortamos y pegamos en un nuevo Word (ctrl + X con la columna seleccionada y ctrl+V en el nuevo Word). Esto lo tendremos que repetir varias veces porque las columnas salen separadas en el Word sucio, por lo que es recomendable abrir los dos Words desde los que vamos a copiar/pegar, uno al lado del otro, para trabajar más fácil.
Una vez que tengamos todas las columnas de filenames pegadas una debajo de la otra, nos quedará un archivo únicamente con los filenames, y el otro con todo el resto del contenido y SIN los filenames.
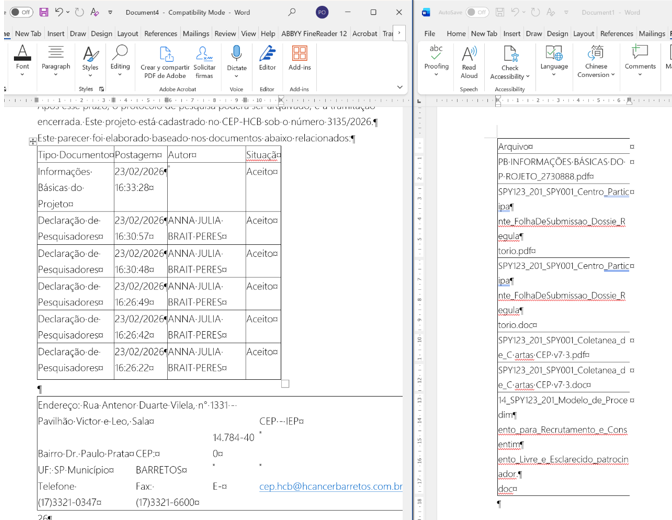
Para obtener el recuento de los filenames, vamos a Buscar y reemplazar (ctrl+L, o ctrl+H si tenemos Word en inglés) y reemplazamos todas las instancias de enter (^p) por nada (lo dejamos vacío).
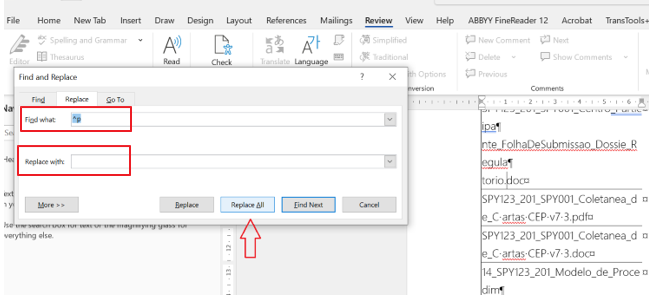
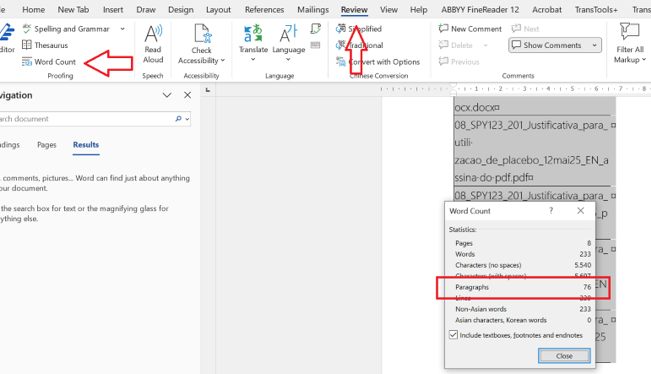
Una vez que tengamos todos los filenames, uno debajo del otro y sin los enters, simplemente miramos la cantidad de párrafos y ya tenemos la cantidad de filenames.
Por otro lado, analizaremos únicamente el archivo SIN filenames normalmente en Trados.
Cargamos el report en Plunet, ponemos las repeticiones y 100% matches en 0 y a las New Words sumamos los filenames x10 (en el ejemplo anterior, deberíamos sumar 760 palabras a las New Words del report). Añadimos las palabras de File prep como siempre, el tiempo correspondiente a bloquear 100% matches y repeticiones (usar calculadora CRM) y ya tenemos listo el presupuesto.
Preparación del proyecto
Una vez que tengamos los Words limpios, resaltaremos la columna de filenames previo a analizar los documentos en Trados. Asegurarse de que la primera fila que dice “Arquivo” quede sin resaltar:

Lo analizamos normalmente con la TM y TB en Trados. Si son varios archivos, los abrimos todos juntos para trabajar en todos a la vez.
Filtramos los 100% matches y los segmentos repetidos, y los bloqueamos.
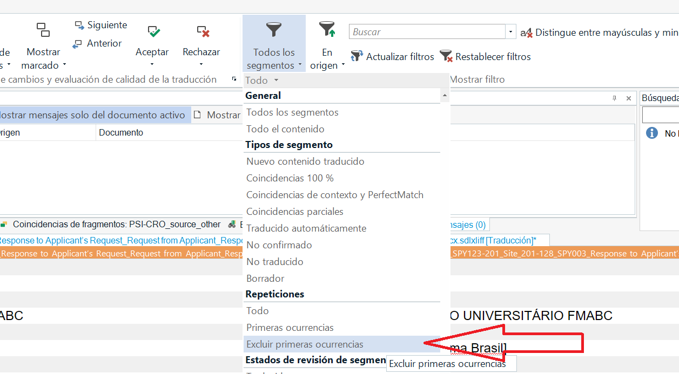
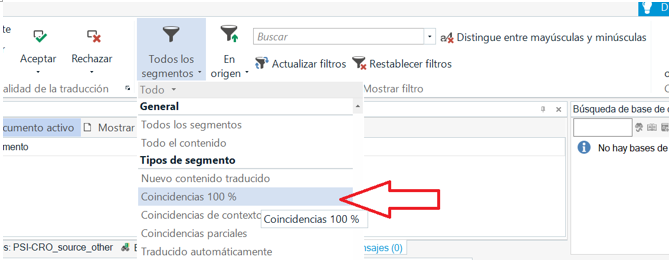
Cuando tengamos los 100% matches y las repeticiones bloqueadas, vamos al advanced display filter y marcamos que nos filtre los segmentos resaltados, que serán todos los filenames. Desbloqueamos todo y guardamos el archivo.
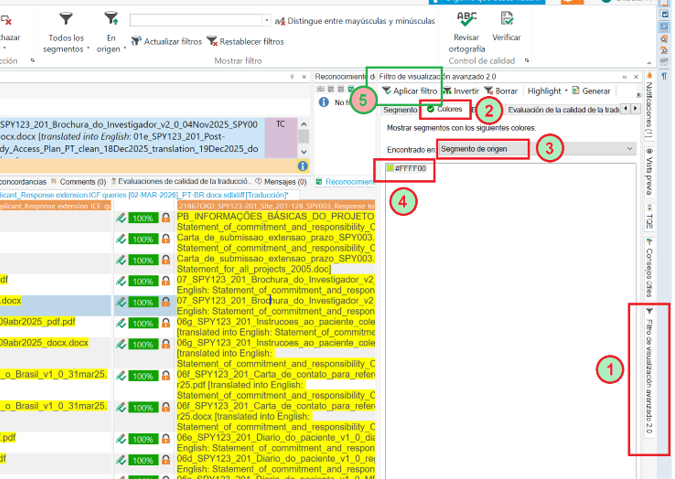
En este punto, ya tenemos los archivos listos para volver a analizar excluyendo los segmentos bloqueados.
Para eso, vamos a Tareas por lotes -> Analizar archivos y marcamos “Excluir segmentos bloqueados del análisis”.
Cargamos ese nuevo report (que nos saldrá en la carpeta del proyecto con un (1)) en Plunet y los sdlxliffs, y lo sacamos a traducir.
La traductora nos dirá cuántas palabras debemos añadir por la traducción de los filenames* y a la revisora debemos añadirle el tiempo según la cantidad de palabras que utilizamos para el cliente (en nuestro ejemplo serías 760 palabras, equivalente a 0,5 horas de revisión).
* En el caso específico de la traductora J.P. (ID Plunet: 255) ella misma nos dice cuántas palabras new debemos añadir (dado que no mira los 100% matches). Si se encarga otra traductora, deberíamos mirar en Trados la cantidad de filenames, diferenciar los new y de los 100% matches (verificando que sean realmente 100% matches, es decir, que salgan con traducción bilingüe como los pide PSI) y añadir la cantidad de palabras correspondiente en cada item.
QA
Una vez que hayamos hecho nuestro QA de los segmentos desbloqueados en Xbench, Okobench y Trados, creamos una nueva TM vacía e importamos el contenido de los sdlxliffs traducidos.
Desbloqueamos todos los segmentos de los sdlxliffs, bloqueamos los filenames, y los analizamos nuevamente, pero esta vez utilizando la TM creada. Verificamos que no nos haya quedado ningún segmento sin traducir (podemos utilizar el filtro “No confirmado”) y ya debería salir todo ok.
Al exportar los Words debemos recordar sacar el resaltado de la columna de los filenames, revisamos formato y ya tenemos los archivos listos para entregar al cliente.