Resource 04 – Herramientas TAO (CAT Tools)
Las herramientas de traducción asistida por ordenador (o herramientas TAO) son programas informáticos que permiten llevar a cabo traducciones de diferentes tipos de archivos, así como almacenarlas en bases de datos denominadas memorias de traducción con el fin de poder reaprovecharlas en futuros proyectos. También facilitan la creación y la gestión de bases terminológicas para luego vincularlas a nuestros proyectos según sea necesario.
El objetivo de este manual es el de proporcionar a traductores y revisores información de utilidad a la hora de trabajar con memorias de traducción (TM, en sus siglas en inglés), en especial con el formato TMX (Translation Memory Exchange), y con los formatos de archivos bilingües usando herramientas TAO (en inglés, CAT-tools). En el mercado hay disponibles muchas herramientas TAO, pero en el presente manual solo trataremos las más usadas entre los profesionales del sector de la traducción, que son las constan en la siguiente lista.
- Déjà Vu X
- Wordfast Classic
- Wordfast Pro
- Trados Studio
- Trados Classic
- memoQ
Antes de hablar de cada herramienta TAO con profundidad, es conveniente tener clara la diferencia entre memorias de traducción y archivos bilingües, por lo que dedicaremos los siguientes párrafos a este tema.
No obstante, también es posible usar el índice o la guía rápida para acceder directamente a las funciones más habituales de cada una de las herramientas TAO en concreto. Gracias a las referencias cruzadas, pretendemos facilitar la navegación en el documento y que encuentre rápidamente la información necesaria en cada caso.
A bilingual file is an intermediate file used by CAT tools in other to obtain the translatable contents from the source files. Each CAT tool includes filters to import several file formats that may slightly vary from one tool to the other. After importing these files, the CAT tool creates bilingual files containing segments from the source and target (if applicable) languages, and in some cases information from the structure of the original file as well. These type of files are intended to enable the typical translation workflows, such as a document being translated by a first user, then edited or proofread by some other user, and verified and finalized by a project manager (PM).
The standard bilingual file format is the XLIFF format. XLIFF stands for XML Localization Interchange File Format and was designed to standardize the handling of translation among different CAT tools so that a linguist working with a specific CAT tool can export the translation and send it to a colleague working with a different CAT software without dealing with any major issues. Any CAT tool should be able to import XLIFF files flawlessly.
Besides XLIFF, CAT tools include their proprietary bilingual file formats. Some of them are based on the XLIFF standard, such as the memoQ MQXLIFF and the Trados Studio SDLXLIFF file formats (as the XLIFF file format can be extended to define new types of information), whereas Wordfast works with a XML variant, the TXML file format. Lastly, some tools (including Wordfast Classic and SDL Trados) use Microsoft Word-based bilingual file formats, such as DOC and RTF variants, so the Microsoft Office Suite must be installed on our computer if we intend to work with these.
Being proprietary file formats; in some cases, it is not so easy to transfer the translations from one CAT tool to another using the bilingual file approach. It either may work flawlessly or almost with no issues or may not be possible at all. In this kind of scenario, the best alternative is to create TMX export files.
In some scenarios, we may need to complete intermediate steps for that purpose. Although the main CAT tools are getting more and more reliable, we ought to keep in mind that working with proprietary file formats and converting file formats back and forth is more subject to errors than working with standard file formats such as XLIFF.
A translation memory is a database designed to store translation units or segments based on segmentation rules (normally sentences). It saves our translations as we work so we can reuse them in other scenarios containing with the same or similar segments.
Differently from bilingual files, a TM contains translated texts that are not limited to a single file or a set of files or to a single project. They may contain segments from one or several files and projects. In other words, a bilingual file contains the text retrieved from the source file only (the end of the source file is the end of the bilingual file), whereas a translation memory does not have any limitations (i.e. the TM can contain as many segments as we want). However, very huge TMs with hundreds of thousands of entries may affect the CAT tool’s performance, especially when doing concordance searches for similar segments.
Just like with bilingual files, there are several proprietary TM file formats depending on the CAT tool, but there is a standard file format which is widely use to interchange TMs, the TMX (Translation Memory Exchange) file format. The TMX files contain the applicable translation units as well as the related fields (project number, Client ID and so on). Almost every CAT tool can import and export TMs in TMX format flawlessly. Nevertheless, the results may vary slightly from one another, as each one handles the format, tags and codes from each segment differently.
| CAT tool | Bilingual file | Obtaining bilingual files | Proprietary TM file format | Exporting a TM to TMX format |
| Déjà Vu X | N/A | Obtaining bilingual files in Déjà Vu X | DVMDB | Exporting target files in Déjà Vu X |
| memoQ | MQXLIFF | With MQXLIFF files | MEMOQTM | Exporting TMX files with memoQ |
| MQXLZ | With MQXLZ files containing a skeleton file | |||
| Trados Classic (2007 and older) | bilingual DOC | Cleaning bilingual files in Trados | TMW | Exporting TMs in Trados |
| Trados Studio (2009 and newer) | SDLXLIFF | Cleaning bilingual files in Studio | SDLTM | Exporting TMs in Studio |
| Wordfast Classic | bilingual DOC | Cleaning bilingual files in Wordfast Classic | TXT | Exporting TMs in Wordfast Classic |
| Wordfast Pro | TXML | Cleaning files in Wordfast Pro | TXT | Exporting TMs in Wordfast Classic |
Similarly to what happens in SDL Trados legacy versions and Trados Studio, nowadays we can differentiate between two opposite approaches in Wordfast.
The first versions of Wordfast, or Wordfast Classic, were designed to be fully integrated in Microsoft Word as add-ons. Just like Trados legacy versions, Wordfast works via Microsoft Words macros that the user can enable via a taskbar installed in that application. Once the translation is complete, the translator will have a bilingual DOC file, similarly to the one used in Trados legacy versions.
As Wordfast Classic was part of Microsoft Word, it was only possible to translate those file formats supported by Microsoft Word. Considering that more and more file formats are created as we speak, it seemed only logical that Wordfast needed to change their approach to prevent their tool from being outdated and not useful for translators.
Consequently, Wordfast designed the standalone versions of this CAT tool, or Wordfast Pro. The Wordfast Pro application is now an independent translation suite where the translation memories, glossaries and bilingual file are available to the translator at the same time in the same window. It now includes filters for a wide variety of file formats, such as InDesign files, that it could not handle before due to the limitations of Microsoft Word.
Just like other CAT tools, Wordfast Pro converts the source file to an intermediate bilingual format. Whereas the XLIFF-variant file format are the basis of MemoQ and Trados Studio, the heart of Wordfast Pro is the TXML bilingual file, a proprietary XML-based bilingual format. Despite being a proprietary file format, it is supported directly by MemoQ and via the File Type Definition for Wordfast TXML plugin for Trados Studio.
As for TMs, the main advantage when working with Wordfast is that the TM file format has not changed from legacy to current version. Wordfast Pro still uses the TXT TM file format which was first implemented in Wordfast Classic. The TXT format is not a database as in other CAT tools, but rather a plain text file which can be opened and edited by standard text editors from outside Wordfast (like TMX files).
Wordfast Classic, as SDL Trados legacy versions, is embedded in Microsoft Word and so the unclean Word file already is a bilingual file with the source text appearing as hidden in Word.
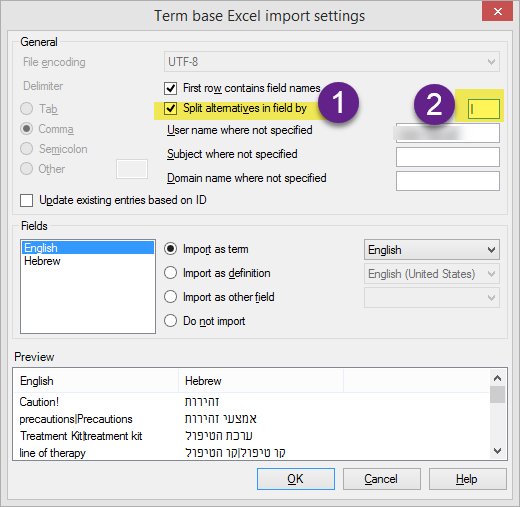
Cleaning bilingual files in Wordfast Classic is very similar to the clean-up process in SDL Trados legacy versions. We just need to open the fully translated Word files in Microsoft Word, press the Wordfast icon in the toolbar (Ctrl + Alt + W) and select the Tools tab in the next window, as highlighted in yellow in the screenshot below.
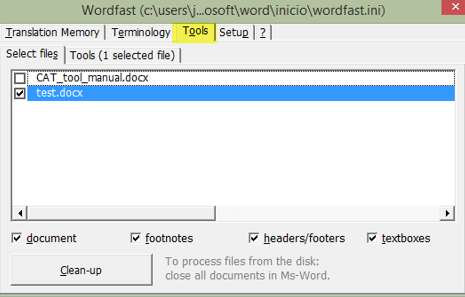
If we press the Clean-up button, the clean-up process (i.e. removing the code Wordfast adds to the file while it is being translated) will begin. A dialog box will pop up to ask us if we want to add the translations to the active translation memory. If we later only want to export the segments from that file (please refer to the section below), we recommend creating a new, empty TM before starting the clean-up process. Once the process is complete, the target files will be saved to the same folder as the bilingual files.
Exporting a Wordfast TM to TMX format can be somehow tricky as the option is more difficult to find than in other CAT tools. The first step is to press the Data Editor Button in the Wordfast toolbar (highlighted in orange in the screenshot below). In the next window we need to go to the Tools tab (highlighted in yellow in the screenshot below).
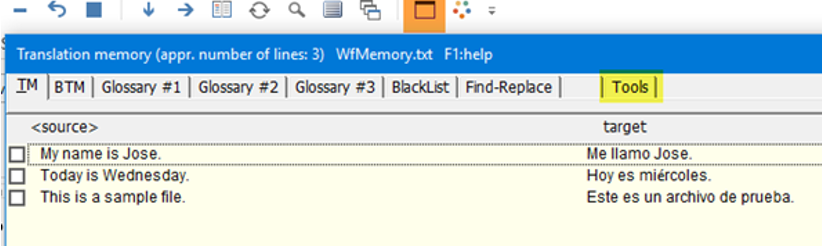
The next step is to choose Export TM as TMX in the Special filters dropdown list as per the screenshot below. At the end of the process, we will obtain a TMX file we can use in other CAT tools or share with our colleagues.
NOTE: although the latest version of Wordfast Pro is version 4, the screenshots are from version 3.4.7. Some icons and labels may be different, but the process is almost the same for both versions.
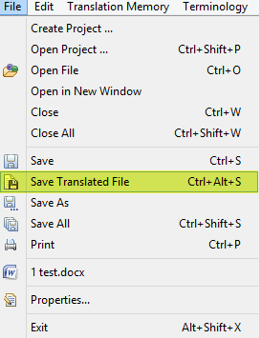
Creating the target files after translation in Wordfast Pro is simple. We just need to go to the File menu and press Save Translated File (Ctrl + Alt + S), as highlighted in the screenshot below.
There are two ways of getting TXML bilingual files from Wordfast Pro, as per below:
- Open the folder containing your Wordfast Pro project, go to the subfolder named after the target language and you will find the TXML files.
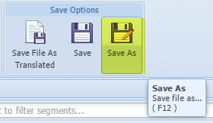
- Alternatively, you can save the files as TXML by going to the File tab > Save Options > Save As or by pressing F12, as shown in the screenshot below.
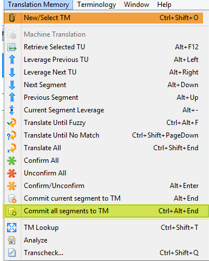
Once we have finished our translation in Wordfast Pro, we can choose between sending all the segments to the project TM or creating a new TM to make sure it contains just the segments from the current project or file. For either purpose, we need to go to the Translation Memory menu and click on New/Select TM (highlighted in orange in the screenshot below).
When the applicable TM is linked to the project, we can send all the translation units of the project at once by going to the Translation Memory menu and clicking Commit all segments to TM (Ctrl + Alt + End) (highlighted in yellow in the screenshot below).
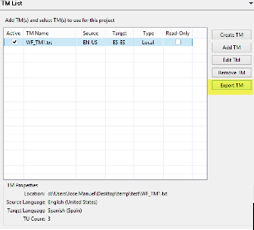
We then need to go to the TM List via Translation Memory > New/Select TM. In the new window, we need to select the TM we want to export and press Export TM, as highlighted in yellow in the screenshot below. We should select the TMX format as the export file if we want to reuse the TM in other CAT tools.
Once the export is complete, the exported TMX file will be saved to the desired folder.
Déjà Vu X is a CAT tool created by Atril, a company based in Paris. Just like almost all CAT tools nowadays, it is a translation suite which shows the translatable files as well as the glossary and translation memory in the same window.
However, it is a peculiar CAT tool as its basis is not a bilingual file format, but rather a database used to store the translatable files and any resources used as references by the translator, such as TMs and glossaries. Thus, the files are not cleaned as in other tools, but rather exported to the final target file (in the same format as the source file).
However, it is possible to exchange our work with colleagues using different tools by exporting it as a standard XLIFF file (supported by almost every CAT tool) or to the bilingual DOC format used by Trados legacy versions. Besides, we can export our stored translation units or segments to a standard TMX file supported by the main CAT tools.
As explained above, the only way to obtain bilingual files in Déjà Vu X consists in exporting them to another format that can be then handled by other CAT tools. As our goal is to use a file which can be used in a wide range of scenarios, we will show you how to export the work we have completed in Déjà Vu X to the XLIFF file format.
As shown in the screenshot below, we need to open the FILE menu in Déjà Vu X and then go to Share > Export > XLIFF and follow the wizard to save each bilingual file to the desired folder selected in Destination.
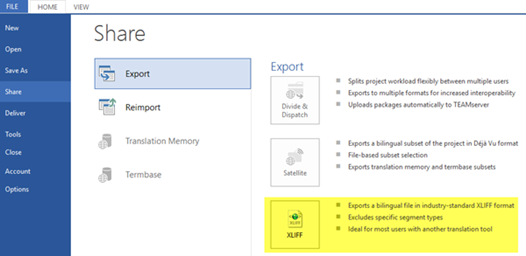
We will obtain a XLIFF file with the XLF extension that we can open in other CAT tools, such as memoQ, as in the screenshot below. We can then add the segments to a TM as described in this guide.

Exporting the target files in Déjà Vu X is simple. We just need to go to the Project Explorer, right click on the project name (the folder on the top level of the project tree) and select Export All to export the target files to the folder selected in Destination.
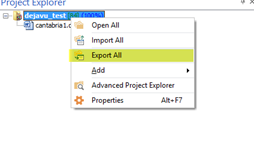
Then we just need to follow the export wizard by selecting the export path and other export options and we will obtain our target files.
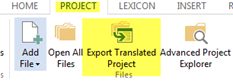
We can also obtain the exported files by pressing the Export Translated Project button placed in the ribbon, under the PROJECT tab and Files group, as per the screenshot below.
Déjà Vu X stores the translation units in a multilingual database with the file format DVMDB (Déjà Vu Memory database). When a DVMDB file is created, Déjà Vu X creates other files (DVMDI and DVDMD) containing the index and language-specific information. Please note you should not either delete or rename them.
When we have finished translating the applicable files, we need to send all the segments to the DVMDB memory linked to the project so that we can later export them without losing any translations. If there is no TM attached to the project, please create a DVMDB TM (project TM) first.
For this purpose, we need to go to the PROJECT tab in the ribbon, then to the Translate group and press the Add to Translation Memory button, as in the screenshot below. Alternatively, we can press Alt + F12 to obtain the same result.

The last step is to export the DVMDB as a TMX file so it can be ready by other CAT tools. For this purpose, we need to open the applicable TM via File > Open. Then we need to go to the External Data tab, Export group and choose TMX, as highlighted in the screenshot below.
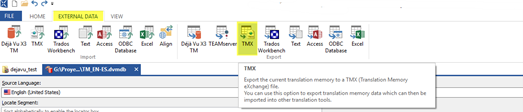
After naming the TMX and following the wizard, we will now have an exported TM which we can keep as a backup, send to colleagues or to the client and so on.
Prior to taking a deeper look into SDL Trados, we need to be completely aware of the differences between the Trados Classic and the Trados Studio versions (2009 and later).
The legacy SDL Trados (from now on, Trados) versions are based on Microsoft Word. These are not standalone applications but rather a set of macros designed to translate files directly in Microsoft Word. Two parallel boxes, one on top of the other, contain both the source text or segment and our translation. In the end we obtain a bilingual DOC Word file where the source file is hidden thanks to a specific Word style. The translation matches are not shown on the same Word window, but on a separate application running in the background, Trados Translator’s Workbench, which works as the database where translated segments are stored, as seen in the screenshot below.
However, soon it was clear that this tool was limited to the file formats supported by Microsoft Word, so they included other tools, including TagEditor, designed to handle non-Office formats such as XML and HTML. For that purpose, TagEditor creates bilingual files in TTX format (an XML variant), while the segments are stored in Workbench as well.
The Trados Translator’s Workbench can be also used for cleaning the bilingual DOC or TTX files (i.e., obtaining the target file on the same format as the source file) while adding the segments to a TM in TMW format. This format is peculiar because it is linked to another 4 files which must be in the same path as the TMW file. If either of them gets corrupted, the TM will not be accessible. After updating the TM with the new segments, it can be later exported to TMX format.
On the other hand, the SDL Trados versions from 2009 on (from now on, Studio), added Studio to their name and became a proper translation suite, similar to Wordfast Pro or memoQ. They are now completely independent from the Microsoft Office suite, with the translatable files, TMs and glossaries together in the same window. Besides, the bilingual file by SDL for the basis of these new versions is another XLIFF variant, the SDLXLIFF file format, similarly to the memoQ MQXLIFF bilingual file.
- Creamos una memoria nueva (vacía):
File > New > par de idiomas > Create (Guardamos la TM en nuestra carpeta privada fuera del servidor. La nombraremos con el nombre que ya tiene nuestra TM, para identificarla mejor posteriormente)
- Importamos la memoria de Okodia:
File > Import
- Cargamos el texto que hay que analizar:
Tools > Analyse > Add (seleccionamos el texto) > Log file (seleccionamos la carpeta propia que habremos creado para ese client job, donde querremos guardar el log y donde tenemos guardado el texto que vamos a analizar) > Analyse
Se guardarán dos archivos:
.log (en formato txt)
.csv
SDL Trados legacy versions are not an independent CAT tool, but rather they work as Microsoft Word templates (the same as Wordfast Classic). This means that the unclean Word file already is already a bilingual file with the source text appearing as hidden in Word, so there is no need to do anything else.
The first step we need to follow to clean bilingual files in Trados is to create a new Translation Memory in the Trados Translator’s Workbench via File > New. We then need to choose the language pair as applicable (as seen in the screenshot below) and select both the TM path and name.
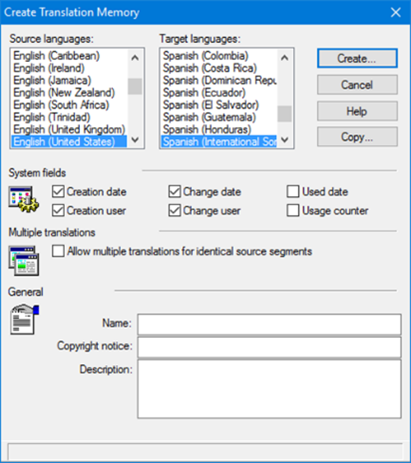
Once created, we should go to Tools > Clean Up. The following window will pop up.
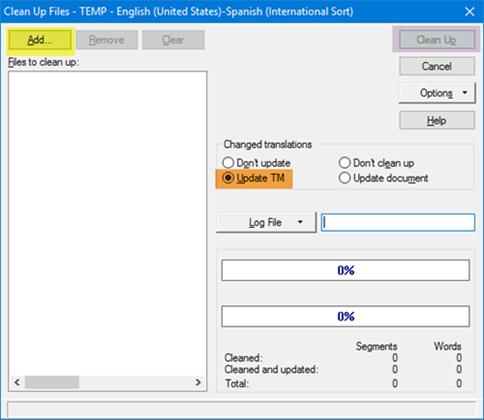
We now have to add the bilingual files we want to clean using the Add button (highlighted in yellow). We should keep in mind that when cleaning TTX files, we should include a copy of the source files (e.g. HTML, PPT, XML) in the same export path so that Trados can create the target file. This is not necessary for bilingual Word files, although we ought to know that Workbench cannot work with Trados Word styles in DOCX files, so we will need to convert any DOCX bilingual files to the DOC legacy file format using Save As in Word first.
After adding the files, we press the Clean Up button (highlighted in orange) and the clean-up process will start. If we select the Update TM option highlighted in orange, the cleaned segments will be added to the TM. We recommend selecting this checkbox so that we can have a copy of the translation and a backup if the clean-up process should fail. If we choose not to select this checkbox, the files will be cleaned but no translations will be added to the translation memory.
If we have selected the Update TM checkbox during the cleanup, we should have a TM containing the segments from the cleaned-up bilingual files. We can export this TM if we go to File > Export. If we want to export all the segments, we just need to press the OK button in the next window and the following Create Export File dialog box below will appear.
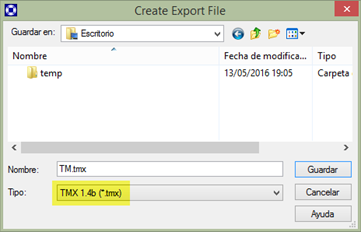
We can choose between several translation file formats. TMX 1.4b, being the standard format, is the one we recommend, as almost every CAT tool supports it.
- Primero creamos el proyecto y cargamos la TM:
File > New > Project
Default > next
Ponemos nombre al proyecto (ej. código del pedido, para identificarlo mejor) > next
Elegimos el idioma origen y el idioma o idiomas de destino > next
- Cargamos el texto que hay que analizar:
Add files > next
- Creamos la TM vacía e importamos la nuestra de Okodia:
Add > File-based Translation Memory (seleccionamos files of type: TMX files o sdltm si ya está creado) > next
Nos saltamos añadir bases de datos, ya que generalmente no usaremos.
Task Sequence: Prepare > next
Batch Processing Settings > next (saldrán los detalles del proyecto) > finish
Cuando se hayan cargado todos los ticks estará todo listo > close
- En la pestaña Reports veremos el análisis. Para guardarlo:
Menú Reports > Save as > .xml
Si necesitamos pasarle el sdlxliff al traductor para que trabaje con él, estará de forma automática en la carpeta donde se guarden los proyectos de Studio (Normalmente, en Este equipo/Documentos/Studio 2017/Projects/Nombre del proyecto). Elegimos los sdlxliff del idioma de destino.
En Studio, la forma más rápida copiar los segmentos de origen en los segmentos de destino es crear un proyecto y luego ir a Configuración del proyecto > Combinaciones de idiomas > Procesamiento por lotes > Pretraducir archivos y marcar las casillas señaladas en esta captura:
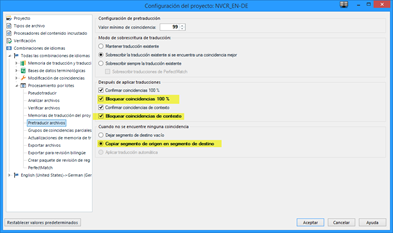
De este modo, los 100 y 101% de la memoria quedan bloqueados y Studio no los cambiará. Además, tendrías el original en el resto de segmentos. También se puede usar la misma función solo para algunos archivos del proyecto en el panel Archivos marcando los archivos correspondientes y luego pulsando Tareas por lotes > Pretraducir.
Otra posible alternativa consiste en instalar el complemento de Studio llamado Segment Actions (http://appstore.sdl.com/language/app/integrated-segment-actions/530/), con Studio cerrado y, una vez instalado, se puede llevar a cabo este mismo proceso en Tareas por lotes > Segment Actions.

Luego solo habría que marcar las siguientes casillas como mínimo:
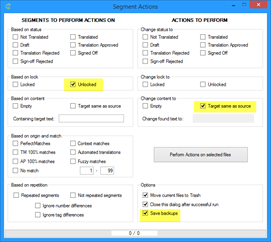
Así se indica al complemento que ignore los segmentos bloqueados (algo importante si las traducciones no deben cambiar) y que el segmento de origen sea igual que el de destino en los demás segmentos. También es recomendable marcar la última casilla para tener una copia de seguridad de los SDLXLIFF.
Suponiendo que ya tenemos un proyecto creado y que hemos importado los archivos de origen correspondientes, tendremos que abrir el archivo correspondiente en el Editor, seleccionar todos los segmentos, hacer clic con el botón secundario del ratón y pulsar en Copiar segmento de origen en segmento de destino. Este paso es necesario porque la exportación no funcionará con segmentos vacíos.
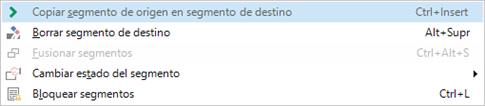
A continuación, tan solo tendremos que ir a la lista de archivos en el panel Archivos y seleccionar los archivos que queremos enviar al traductor externo. Luego usaremos la función Tareas por lotes > Exportar para revisión bilingüe, como vemos en la siguiente captura de pantalla.
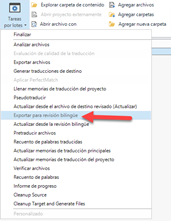
Entonces aparecerá la siguiente ventana, donde dejaremos las opciones predeterminadas sin cambiar, salvo la ruta donde queremos guardar el archivo.
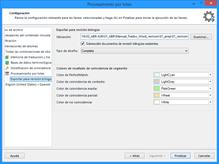
Una vez concluido el proceso, veremos que Studio ha creado un archivo con la extensión review.docx. En este punto, es importante señalar que no hay que modificar este archivo, ni cambiarlo de carpeta o de nombre, ya que Studio lo usa como plantilla y el proceso contrario dará error si lo modificamos.
Una vez el traductor abra este nuevo archivo en Word para traducir, tendrá que limitarse a traducir en la columna de destino, donde sus traducciones aparecerán con control de cambios (ya que es un formato ideado para revisión y no para traducción), tal y como se aprecia en esta captura de pantalla.

Una vez haya terminado de traducir, tan solo tendrá que guardar el archivo DOCX para que no se pierdan los cambios. Cuando el traductor haya terminado su trabajo, tendremos que importarlo de vuelta en Studio, no sin antes recordar que no hay que sobrescribir el archivo creado por Studio en el paso inicial. Para ello, usaremos Tareas por lotes > Actualizar desde la revisión bilingüe, según se señala en la imagen.

En la ventana que aparecerá, tendremos que usar la función Agregar > Documento de revisión específico (si solo es un archivo) o Documentos de revisión de la carpeta si hay varios archivos actualizados (traducidos) en una misma carpeta).
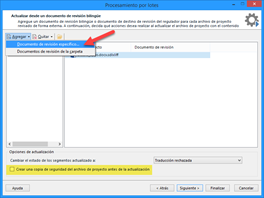
Entonces solo queda añadir el archivo review.docx del traductor, marcar la casilla Crear una copia de seguridad del archivo de proyecto antes de la actualización por si acaso y pulsar Finalizar.
Si todo va bien, al abrir el archivo de nuevo en Studio veremos los cambios con control de cambios, como se aprecia en esta captura de pantalla:
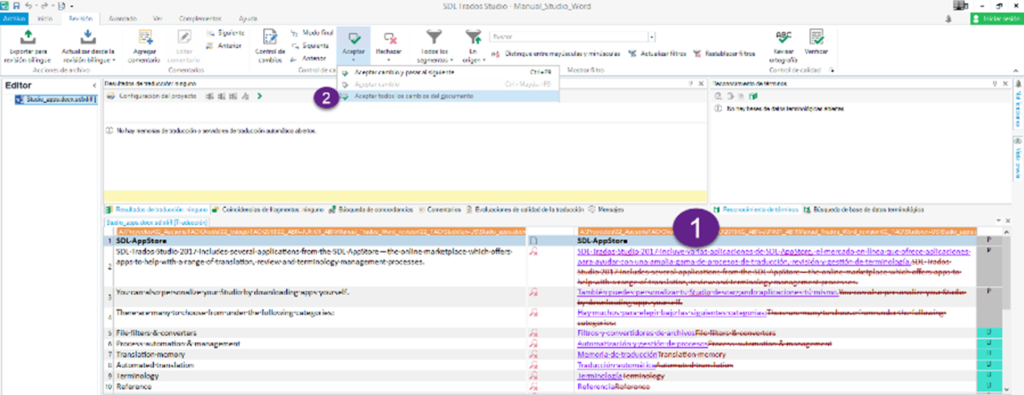
Lo único que quedaría por hacer sería aceptar todos los cambios yendo a la pestaña Revisión > Aceptar > Aceptar todos los cambios del documento. Por último, es recomendable seleccionar todos los segmentos y usar la función Cambiar estado del segmento > Traducido y guardar el SDLXLIFF con Ctrl + S para que se pueda actualizar la memoria correspondiente.
El objetivo de este manual consiste en mostrar brevemente qué son los filtros de archivo y, en concreto, cómo añadir nuevos filtros a Trados Studio (de ahora en adelante, Studio) para poder aplicarlos a las traducciones que gestionemos con esta herramienta TAO.
Por lo tanto, antes de pasar al proceso para añadir filtros a Studio, en los siguientes párrafos veremos algunos conceptos básicos que ayuden a aclarar el concepto de filtros de archivo.
Dicho en pocas palabras, un filtro de archivo es una lista de instrucciones que indican a la herramienta TAO en cuestión (en nuestro caso, Studio) qué contenido traducible debe importar y cómo debe importarlo y el contenido que quedará excluido, oculto a la vista de quienes trabajen en el proyecto.
Studio, al igual que las demás herramientas TAO, incorpora de serie una gama de filtros que definen el contenido traducible en los formatos de archivo más habituales, como pueden ser DOC(X), PPT(X), HTML, TXT y tantos otros. Además, de forma predeterminada, estos filtros vienen configurados del modo que mejor se adapta a las necesidades de la mayoría de los traductores en la mayoría de proyectos de traducción, pero, como no todos esos proyectos son iguales, hay cierta libertad para cambiar esos filtros, ya sea de modo general o para un proyecto o archivo en concreto.
Por poner un ejemplo, cuando queramos traducir una presentación de Power Point, podremos cambiar la configuración del filtro según queramos incluir o excluir el contenido de las notas del presentador. La siguiente captura de pantalla muestra que hay tres opciones disponibles para decidir lo que queremos hacer con las notas.

No obstante, hoy hay casi tantos formatos de archivo como uno se pueda imaginar, y ese número no deja de aumentar cada día. Por tanto, es imposible que una herramienta TAO pueda incluir todos. Además, algunos filtros solo serían utilizados unas pocas veces, por lo que no parecería una decisión justificada.
Dicho esto, Studio permite sumar nuevos filtros a la lista de los ya existentes. Para tal fin, podemos usar dos vías: crearlos nosotros mismos si es que tenemos el tiempo y los conocimientos necesarios, o bien importar un archivo de configuración de filtro que provenga de otro profesional que lo haya creado por sí mismo. Ya usemos la primera o la segunda vía, el resultado final será el mismo, y ya podremos importar el contenido traducible de esos archivos intocables hasta ese momento.
Este último párrafo también se puede aplicar a algunos formatos de archivo muy flexibles para los que Studio ya tiene filtro propio. El archivo multiusos por excelencia es el XML, que se puede personalizar de infinitas formas. Studio puede importar archivos XML, y mostrará el contenido traducible a la perfección siempre que cumpla con el estándar.
Sin embargo, en cuanto se salga de ese estándar (lo que ocurre en la mayoría de los casos), el filtro fallará y omitirá contenido traducible o mostrará contenido que no se debe tocar. En estas situaciones, contar con un filtro de archivo propio y personalizado evitará quebraderos de cabeza y garantizará que traduciremos todo lo traducible sin que afecte a la integridad del archivo cuando exportemos el archivo de destino desde Studio.
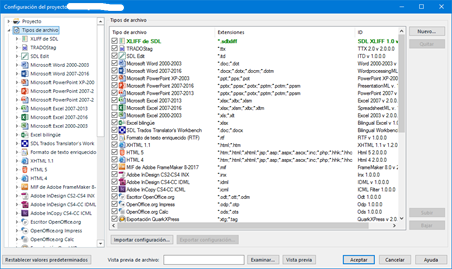
En Studio podemos modificar o añadir filtros en dos niveles: de forma global (es decir, los cambios que hagamos se trasladan a todos los proyectos futuros hasta que anulemos esos cambios), o bien en un proyecto concreto, ya que es posible que haya cambios que no nos interesa que queden reflejados en los proyectos posteriores. La ventana que muestra la lista de filtros y su configuración es idéntica en ambos casos, pero se accede a ella de formas diferentes:
- De forma global: tendremos que pulsar el botón Archivo (situado en la esquina superior izquierda), luego ir a Opciones y en Tipos de archivo veremos la lista.
- Según el proyecto: cuando hayamos abierto un proyecto, en la esquina superior izquierda veremos el botón Configuración del proyecto, como muestra la siguiente captura de pantalla. Tras hacer clic en él, en la sección izquierda de la siguiente ventana veremos la lista en Tipos de archivo.
La siguiente imagen permite echar un vistazo general a la lista de filtros de archivo. En la sección izquierda, cada tipo de archivo tiene una flecha que despliega a su vez todas las opciones que podemos configurar para cada formato en concreto. Por otro lado, en la sección central, veremos que a la izquierda de cada formato hay una casilla de verificación que activa o desactiva el filtro.
Llegados a este punto, mencionaremos las reglas que emplea Studio para aplicar los filtros cuando procesamos archivos traducibles.
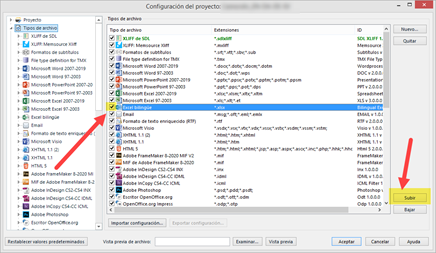
- En primer lugar, Studio solo tiene en consideración los filtros activados (es decir, con un tic en la casilla de verificación). Aunque exista el filtro que queramos usar en la lista, si está desactivado, Studio no lo empleará.
- Además, Studio consulta la lista y busca el mejor filtro en función de la extensión del archivo que se quiera importar. En caso de que haya varios filtros activos para la misma extensión, Studio utilizará el primero que encuentre buscando desde arriba en la lista. Así pues, para garantizar que Studio recurre al filtro deseado, podemos usar el botón Subir para colocarlo lo más arriba en la lista. Si no, también serviría desactivar los filtros activos para la misma extensión de archivo que no nos sirvan en ese momento.
En esta ventana es donde crearemos o añadiremos nuevos filtros que permitan importar el contenido traducible de los archivos para los que no exista un filtro predeterminado o para los que el filtro predeterminado no se ajuste perfectamente. En la sección 5.4.5 explicamos cómo importar filtros de archivo en Studio.
Como hemos explicado en las páginas anteriores, Studio cuenta con un número limitado de filtros de archivo que puede quedarse corto en algunas circunstancias. Por ello, siempre es posible añadir nuevos filtros que suplan las carencias de esta herramienta TAO.
En pocas palabras, un filtro de archivo no es más que un archivo de texto que contiene instrucciones para que Studio interprete de forma correcta cómo tiene que importar los archivos de determinada extensión para su traducción. Hay dos tipos de archivos que se pueden importar según la versión de Studio, pero, a grandes rasgos, ambos cumplen la misma función.
Versión 2009: archivo sdlfiletype.
Versión 2011 y posteriores: archivo sdlfltsettings.
La importación del nuevo filtro es muy sencilla. Tan solo debemos tener en cuenta si queremos añadir el filtro a un nuevo proyecto únicamente o bien hacerlo de forma global para que esté siempre disponible. La opción más lógica es la segunda.
Para importar el nuevo filtro de forma global, iremos a Archivo > Opciones > Tipos de archivo y haremos clic en el botón Importar configuración, como en la siguiente captura. A continuación, buscaremos el archivo sdlfiletype o sdlftsettings correspondiente.
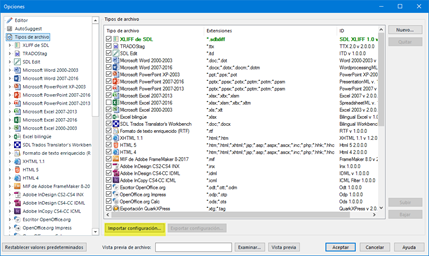
Aparecerá la siguiente ventana, donde haremos clic en el botón Sí.
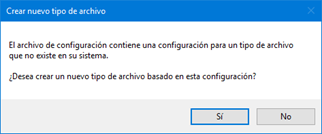
Si todo va bien, ahora ya podremos ver el nuevo filtro en la lista. En este caso, se trata de un filtro para archivos properties, como muestra la captura.

Desde este momento, ya podremos importar archivos con la extensión correspondiente y traducirlos sin mayores problemas. Tan solo tenemos que estar seguros de que el filtro está activo en la configuración del proyecto y que no esté en conflicto con otros filtros para la misma extensión de archivo, tal y como vimos cuando explicamos las reglas que sigue Studio a la hora de decidir el filtro apropiado para preparar un archivo para traducción en la sección Filtros en Studio.
Acabamos de ver cómo importar un filtro de forma global en Studio. No obstante, siempre que creamos un proyecto, también podremos importar ese filtro, o bien activar y desactivar otros filtros para la misma extensión de archivo con el fin de que Studio elija el apropiado en cada caso.
Para ello, tan solo es necesario pulsar Ctrl + N o ir a Archivo > Nuevo > Nuevo proyecto. Entonces se abrirá el asistente para la creación de proyectos, el cual seguiremos hasta el cuarto paso, Archivos de proyecto. Si hacemos clic en el botón >> situado en la parte derecha de la ventana (señalado en la siguiente captura) y luego en Tipos de archivo, accederemos a una ventana similar a la mostrada antes en este manual.
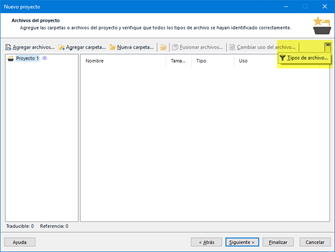
Llegados a este punto, solamente queda importar el filtro escogido y hacer los cambios en los demás filtros (modificar opciones, activar o desactivar, etc.) según nuestras necesidades y según lo que vimos en la sección anterior, Importación de filtros en Studio, y siempre teniendo en cuenta las reglas que emplea Studio a la hora de decidir el filtro para procesar un archivo de una extensión determinada.
Cuando hayamos terminado, pulsaremos el botón Aceptar y volveremos al asistente de creación de proyectos. Tras concluir la creación del proyecto, Studio importará los archivos deseados según le hayamos indicado en Tipos de archivo.
En el caso de que hayamos importado filtros personalizados, tendremos disponibles varios filtros para la misma extensión de archivo. Dado que Studio utiliza el primer filtro activo que encuentra en la lista empezando desde arriba para procesar los archivos, si queremos que Studio use un filtro en concreto, tendremos que forzarle a que lo haga, bien desactivando las casillas de los filtros que no nos interesan (1) o bien desplazando el filtro adecuado en la lista mediante el botón Subir (2).
Por último, como conclusión a este manual, cabe recordar que también es posible exportar estos filtros para compartirlos con otros profesionales. Para tal fin, lo único que hay que hacer es pulsar el botón Exportar configuración en la ventana Tipos de archivo y enviar el archivo resultante al destinatario.
Las versiones más recientes de memoQ y Trados Studio pueden procesar el contenido de archivos incrustados en archivos de Word. Sin embargo, hay que tener en cuenta una serie de limitaciones:
- El archivo de Word tiene que tener la extensión DOCX y no DOC, pues los archivos en DOC no manejan bien los archivos incrustados, y las herramientas TAO tampoco podrán extraerlos. Si alguno de los archivos es DOC, hay que guardarlo como DOCX antes de importarlo en una herramienta TAO.
- Ahora mismo, memoQ y Studio solo reconocen el contenido traducible si los archivos incrustados son hojas de Excel. En algún caso de gráficos editables, es posible que la TAO también pueda extraer el contenido, pero en ocasiones, como en los gráficos hechos con Visio, tendremos que extraer el contenido manualmente. En la sección se explica este proceso con más detalle.
- En algún caso, al abrir el DOCX de destino, veremos que la hoja de Excel sigue en el idioma original. Ello se debe a que las hojas de Excel son campos de Word que hay que actualizar, para lo que pulsaremos Ctrl + E/A para todo el contenido y, a continuación, pulsaremos F9 para actualizar todos los campos.
Si queremos que Studio procese las hojas de Excel incrustadas, tendremos que cambiar la configuración del filtro de Word 2007-2013 en Configuración del proyecto según la siguiente captura antes de importar los archivos DOCX de origen para que Studio tenga dichas hojas en cuenta.
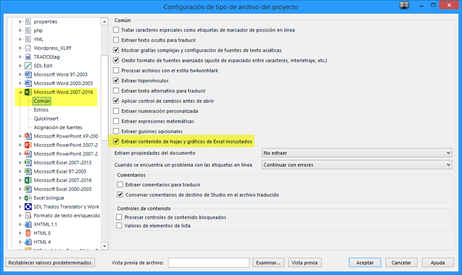
Sin embargo, esta opción es nueva de Studio 2017 y todavía no está muy bien pulida, por lo que en ocasiones puede que Studio no reconozca las hojas incrustadas y, por esa razón, tengamos que recurrir a memoQ o a la extracción manual de las hojas de Excel, tal y como se explica en la sección 6.3 de este mismo manual.
Una vez hayamos terminado de traducir, lo único que queda es exportar los archivos siguiendo el proceso normal, abrir el archivo DOCX y actualizar los campos con F9, tal y como se ha explicado anteriormente.
Si todo lo anterior fallara, todavía nos queda extraer de forma manual las hojas de Excel de los archivos DOCX siguiendo este proceso:
- Hacemos una copia de seguridad de los archivos DOCX de origen.
- Como los archivos DOCX en realidad son archivos comprimidos, podemos cambiar la extensión de DOCX a ZIP para ver sus contenidos con un extractor de archivos comprimidos como WinRar.
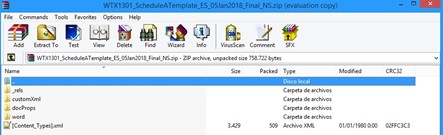
- Si navegamos a la carpeta word > embeddings, veremos las hojas de Excel incrustadas:

- Ahora podemos extraerlas e importarlas en la herramienta TAO de turno junto con el DOCX siguiendo el proceso normal.
- Una vez traducido todo, exportaremos los archivos desde la herramienta TAO.
- Ahora tenemos que hacer una copia de seguridad del archivo DOCX de destino y cambiar su extensión por ZIP.
- Después seleccionamos las hojas de Excel traducidas y las arrastramos y soltamos hacia la carpeta word > embeddings de este nuevo ZIP.
- Pulsamos pulsar el botón Aceptar cuando el programa nos pregunte si queremos actualizar el contenido del archivo ZIP y volvemos a cambiar la extensión a DOCX.
Even though the several Studio versions (2009, 2011, 2014 and 2015) are different from one another, the process to clean bilingual files in this CAT tool is the same. The steps below thus applies to all versions, although the screenshots only match the 2014 version and the names and locations of the options may be slightly different.
Considering we have a project with the applicable language pairs, there are several possible scenarios:
- Our client has provided us with the source files and we have converted them to the SDLXLIFF file format using Studio.
- Besides having received the files in the source file format, our client has sent us the SDLXLIFF files already prepped for translation, which can be either separately or as part of a package so that we can start translating them at once.
- We only have the SDLXLIFF bilingual files to translate, which or client can send separately or as part of a translation package.
We will be able to export the target file depending on the preferences of our client as well as on the source file format. For some formats such as DOC(X) or HTML, we can usually merge the bilingual file (i.e., creating the target file) even if we do not have the source file, whereas that may not be the case with other source file formats such as PPTX.
For confidentiality reasons, our client may not want us to be able to merge the bilingual files. In scenarios where we need to create the target file, it is always advisable to ask for the source files as we can use them to create SDLXLIFF files on our side we can then pretranslate and export if merging the SDLXLIFF files provided by our client should fail.
When the project is complete and we are ready to create the target files, we need to select the applicable files in the Files pane (if we press Ctrl + A, all the files will be selected) and then choose Batch Tasks > Generate Target Translations in the dropdown menu as per the screenshot below.
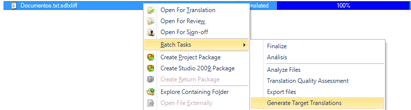
We only need to follow the wizard and the export process will start. If the process is completed successfully, a Studio dialog box will pop up and take us to the target folder (normally the subfolder named as the target language code inside the project folder) if needed.
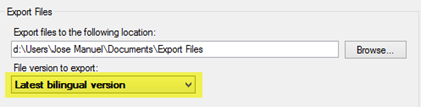
We can export the bilingual files in SDLXLIFF from a project by following these steps:
- Select the applicable files on the Files pane.
- Right click and go to Batch Tasks > Export Files.
- In the next window, select Latest bilingual version in the dropdown menu, change the path to the desired folder and click on OK to save the SDLXLIFF files.
Alternatively, you can take the SDLXLIFF bilingual files from the folder named after the target language under the folder where you have saved your project during the New Project wizard.
Para exportar todos los archivos de destino a la vez en Studio:
- En el proyecto que sea, ve al panel Archivos y luego elige al idioma de destino al que pertenezcan los archivos que quieres exportar.
- Si quieres escoger todos los archivos de todas las carpetas y subcarpetas, marca la casilla Incluir subcarpetas (te la señalo en naranja en la captura adjunta). Si solo quieres exportar los archivos de una misma carpeta, déjala desmarcada.
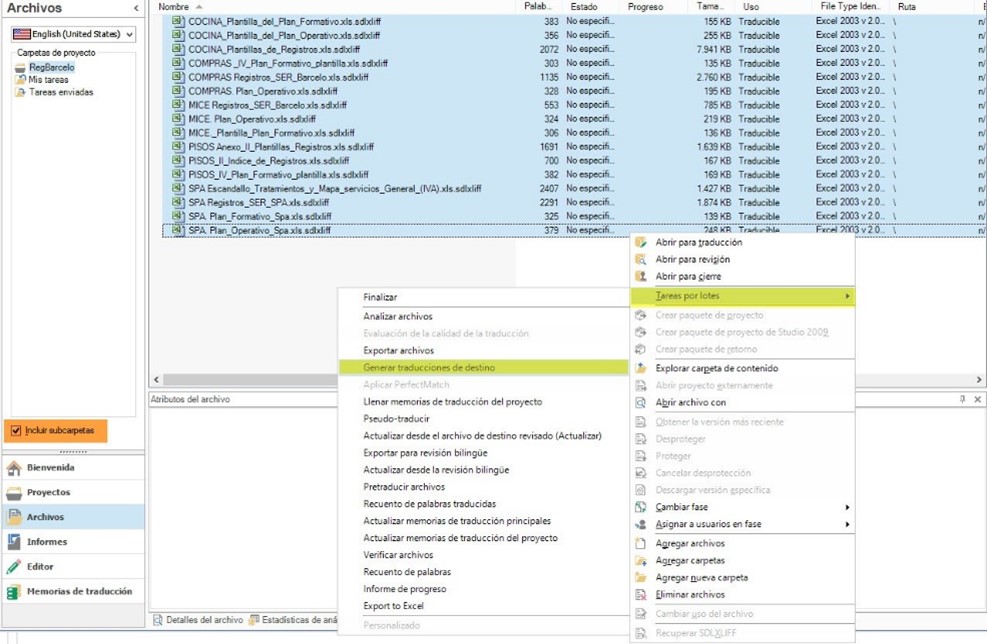
- Selecciona todos los archivos pulsando Ctrl + A (de all).
- Haz clic con el botón secundario del ratón, elige Tareas por lotes en la lista desplegable y luego pulsa en Generar traducciones de destino (ambas marcadas en amarillo en la captura).
- En el asistente que aparece, pulsa Siguiente y
- Cuando termine el proceso, aparecerá un cuadro de diálogo que te llevará a la carpeta donde están guardadas las traducciones si así lo quieres.
The best way to make sure that only the segments from a specific project are part of a TM is by creating a new TM at the end of the project with the same language pair as the finished translation project. Once we have the new TM in the Studio proprietary SDLTM format, we need to open it in the Translation Memories pane, select it, right click on it and go to the Import option from the menu as per the screenshot below.
We then have to navigate to search the translated bilingual file (typically, SDLXLIFF files), select them and follow the wizard modifying any options as applicable. We will see the translation units are now part of the TM.
Exporting this updated TM is very easy. In the same menu as in the screenshot above, we should choose the Export option. If we follow the wizard as per default, we will obtain a TMX export file we can use within other CAT tools.
Alternatively, we can create SDLTM and their corresponding TMX export files from single SDLXLIFF or TTX files without even opening a single Studio instance by using a very simple Studio App, QuickTMXExportImport. We can download it from the link below, where we can find a basic tutorial to learn how it works:
http://translator-banks.blogspot.com.es/2014/11/quicktmexportimport-app-for-trados.html
Suponiendo que ya tenemos un proyecto creado, el primer paso es importar los archivos de origen para obtener el archivo SDLXLIFF con los segmentos frecuentes. Para ello, pulsaremos el botón Agregar archivos y, a continuación, los seleccionaremos en la lista y haremos clic en Tareas por lotes > Preparar sin la memoria de traducción del proyecto.
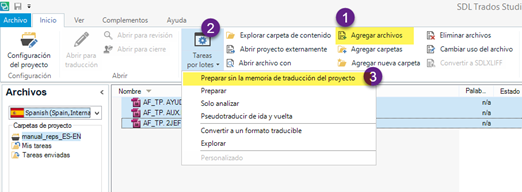
En el asistente que aparecerá, la opción que más nos interesa se encuentra en Procesamiento por lotes > Analizar archivos, tal y como se señala en la siguiente captura. En esa sección veremos el apartado Segmentos frecuentes, donde marcaremos la casilla Exportar segmentos frecuentes. Además, como queremos que el número de palabras sea el mínimo posible, cambiaremos el número de ocurrencias a 1 (NOTA: algunas veces Studio se bloquea al intentarlo y hay que cambiar este valor a 2).
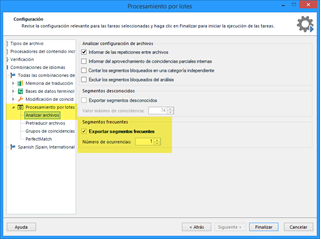
Tras pulsar el botón Finalizar, Studio convertirá los archivos de origen al formato SDLXLIFF y guardará el archivo de repeticiones en la carpeta Exports dentro de nuestro proyecto de Studio. Este será uno de los archivos que enviaremos al traductor y al revisor.

Una vez hayamos obtenido el archivo SDLXLIFF de repeticiones, tendremos que seguir varios pasos hasta conseguir separar las repeticiones de las no repeticiones en el archivo SDLXLIFF principal en Studio. Para llegar a ese punto, lo primero que haremos será importar el archivo de repeticiones y prepararlo como si se tratara de otro archivo de origen.
Terminado el paso anterior, vamos a fingir que traducimos el archivo de repeticiones (pseudotraducción) para poder enviar los segmentos a una memoria temporal y después averiguar dónde están esos segmentos (las repeticiones) en el archivo principal.
Así pues, tras asegurarnos de que estamos en el idioma de destino, seleccionaremos el archivo de repeticiones e iremos a Tareas por lotes > Pseudotraducir, tal y como se ve en la siguiente captura:

En el asistente de pseudotraducción dejaremos las opciones predeterminadas y esperaremos a que termine el proceso. Si abrimos el archivo, podremos observar el resultado de la pseudotraducción.
Ahora tenemos que enviar esos segmentos a una memoria, para lo cual crearemos una memoria de traducción temporal en Configuración del proyecto. Conviene quitar cualquier otra memoria de la lista para evitar el riesgo de que se «contamine» con segmentos pseudotraducidos.
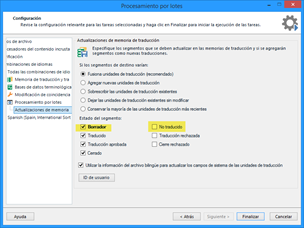
Después de añadir la memoria a la lista, usaremos la función Tareas por lotes > Actualizar memorias de traducción principales para enviar dichos segmentos a esa memoria.

En la ventana que aparecerá, es importante marcar la casilla Borrador y No traducido para cerciorarnos de que los segmentos van a la memoria.
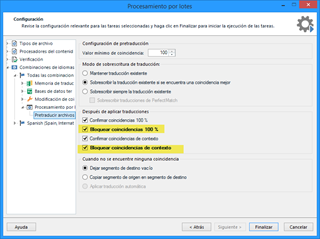
Ahora que tenemos los segmentos en la memoria, la vamos a emplear para pretraducir el archivo principal con el propósito de aislar los segmentos que son repeticiones de los que no lo son. Por lo tanto, el siguiente paso es seleccionar el archivo principal y después ir a Tareas por lotes > Pretraducir.
En la ventana que aparecerá, marcaremos las casillas para bloquear las coincidencias 100 % y las coincidencias de contexto (o 101 %), respectivamente. El bloqueo nos servirá como criterio para localizar de forma rápida las repeticiones en el archivo principal.
Una vez hemos pretraducido el archivo, el siguiente paso consiste en eliminar esas pseudotraducciones del archivo principal pero manteniendo el bloqueo para que se vean las repeticiones a simple vista, ya que luego se lo enviaremos al traductor como archivo de no repeticiones.
Tras abrir el archivo, usaremos los filtros de segmentos para que Studio muestre únicamente los segmentos bloqueados (es decir, las repeticiones), tal y como se muestra en la captura.
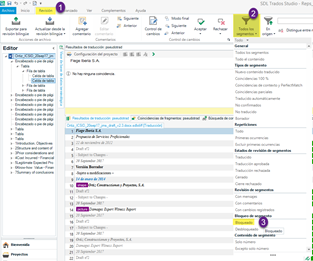
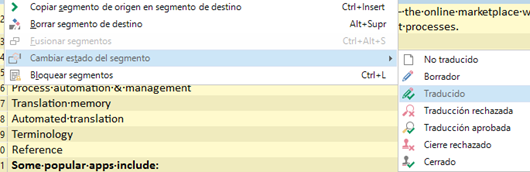
A continuación, borraremos el contenido de esos segmentos, para lo cual hay que desbloquearlos primero. Así pues, seleccionaremos todos los segmentos y pulsaremos la combinación Ctrl + L. Acto seguido, haremos clic con el botón secundario del ratón y escogeremos la opción Borrar segmentos de destino.
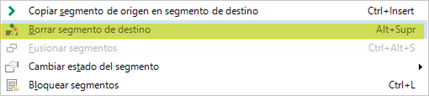
Para terminar, volveremos a bloquear los segmentos con la misma combinación de teclas. Después pulsaremos Ctrl + S para guardar el archivo SDLXLIFF, el cual trataremos como archivo de no repeticiones. Ya se lo podremos pasar al traductor, al que habrá que indicarle que no cambie los segmentos bloqueados.
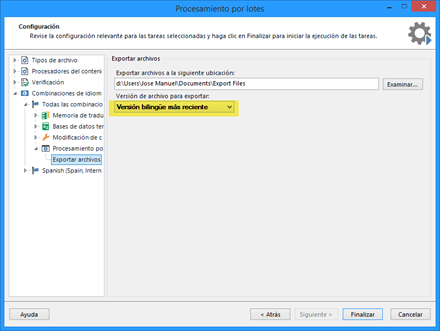
Para obtener el archivo SDLXLIFF, usaremos la función Tareas por lotes > Exportar archivos con la opción Versión bilingüe más reciente, tal y como se resalta en la captura de pantalla.
Una vez hayamos recibido los archivos de repeticiones y de no repeticiones ya traducidos o revisados, el siguiente paso consiste en importarlos en vuelta en el proyecto. Para ello, los copiaremos y pegaremos en la carpeta del idioma de destino que se encuentra dentro de la carpeta del proyecto de Studio para que sustituyan a los no traducidos (se recomienda hacer una copia de seguridad de los SDLXLIFF en este punto).
Tras esta operación, tendremos que indicarle a Studio que actualice el porcentaje del trabajo completado para que muestre que están traducidos (en vez de un 0 %). Para tal fin, usaremos la función Tareas por lotes > Recuento de palabras traducidas.

Si todo va bien, Studio actualizará los porcentajes. El archivo de repeticiones debería estar traducido al 100 % (salvo en casos concretos), mientras que el de no repeticiones no estará completo a causa de los segmentos que bloqueamos anteriormente.

Cuando hayamos importado las traducciones en Studio, la tarea más importante que queda es pretraducir los segmentos repetidos en el archivo SDLXLIFF principal usando las traducciones ya existentes en el archivo de repeticiones.
Por lo tanto, ahora tendremos que crear una nueva memoria de traducción en Configuración del proyecto (sin olvidarnos de quitar de la lista la memoria que usamos para la pseudotraducción) y enviar los segmentos del archivo de repeticiones a la memoria nueva según vimos en el paso 5.9.2.
Por otra parte, puesto que todavía tenemos segmentos bloqueados en el archivo principal, tendremos que desbloquearlos antes de poder pretraducirlos. Así pues, abriremos dicho archivo, usaremos los filtros de segmentos para que solamente aparezcan los segmentos bloqueados y los desbloquearemos del mismo modo que hicimos en el paso 2.5.
Ahora sí podremos usar la función Tareas por lotes > Pretraducir archivos para que se añadan las traducciones de las repeticiones al archivo principal. El porcentaje ahora será del 100 % o casi del 100 % (puede ser necesario añadir alguna traducción desde la memoria por cuestiones de formato o similares).
Tras todos estos pasos, ya podremos crear nuestro archivo de destino. Para ese fin, tan solo tendremos que usar la función Archivo > Guardar destino como, o bien podemos recurrir a la alternativa Tareas por lotes > Generar traducciones de destino (en especial si el proyecto está formado por varios archivos), tal y como se resalta en la siguiente captura de pantalla.
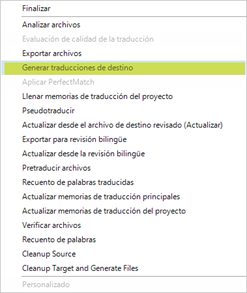
Una vez terminado el proceso, ya será posible abrir los archivos traducidos con el programa correspondiente, hacer las comprobaciones oportunas y enviárselos de vuelta al cliente.
Uno de los apartados más importantes cuando traducimos es el referente a la terminología. En Trados Studio es posible usar bases de datos terminológicas de Multiterm, en formato SDLTB, tanto para la consulta y gestión de términos como de cara al control de calidad en nuestros proyectos.
Sin embargo, a menudo los clientes u otros compañeros pueden facilitarnos glosarios en formatos alternativos, como el XLSX de Excel. Dichos glosarios pueden limitarse a una columna por idioma o a más columnas para definir diferentes campos, tal y como se aprecia en esta captura de pantalla.
Cuando hayamos guardado el archivo con los cambios, el siguiente paso es convertirlo al formato SDLTB, propio de Multiterm, un programa creado también por SDL e ideado para la creación y gestión de bases terminológicas. Después podremos usar bases en formato SDLTB en nuestros proyectos de Studio, tal como explicaremos en el apartado Cómo añadir la base terminológica a un proyecto de Studio.
Sin embargo, puesto que Multiterm no es el programa más sencillo de dominar del mundo si nos estamos iniciando en las herramientas TAO y las bases terminológicas, hacer esta conversión a la primera es muy complicado, por lo que muchos usuarios desisten y apartan la terminología a un lado.
Sin embargo, no todo son malas noticias. Para facilitarnos el proceso de conversión del formato XLSX original a SDLTB, contamos con la inestimable ayuda de Glossary Converter, una de las muchas apps gratuitas que podemos descargar desde la SDL AppStore, similar a la Play Store o la AppStore, y a la que podemos acceder siempre que tengamos licencia de Trados Studio.
Glossary Converter es una app de interfaz muy sencilla que convierte al formato que decidamos archivos de diferentes formatos usados para crear bases terminológicas. Después de descargar Glossary Converter, instalaremos la app y la abriremos. Si pulsamos el botón configuración, accederemos a todos los ajustes que tendremos que cambiar en la app.

En nuestro caso, nos interesa elegir la primera pestaña, General, y asegurarnos de que está marcada la primera opción, MultiTerm Termbase. En las demás pestañas podremos cambiar otros parámetros si así lo necesitamos, pero en este ejemplo podemos usar las opciones predeterminadas.
El siguiente paso es muy sencillo: basta con abrir la carpeta donde tenemos guardado nuestro archivo XLSX, seleccionarlo y arrastrarlo y soltarlo en la ventana de la app para que dé comienzo el proceso, cuya duración dependerá del tamaño del glosario. Esta app cuenta con una base de datos de campos frecuentes que crea a partir del nombre de las columnas del archivo XLSX, pero nos mostrará un mensaje de aviso similar al de la siguiente captura si tiene dudas durante la conversión.
Si se diera el caso, tendríamos que decirle a Glossary Converter, en primer lugar, en qué nivel queremos ubicar el campo en cuestión: nivel de entrada (en campos relativos a todos los idiomas, como el área de especialidad, el nombre del cliente o de quien ha añadido el término, etc.), nivel de índice (para aquellos campos que dependen de un idioma en concreto, como puede ser la categoría gramatical) o nivel de término (que son campos vinculados a un término en concreto, como un ejemplo de uso, el nivel de formalidad, si es de uso prohibido, etc.).
Además, tendríamos que indicarle a la app haciendo clic en el botón Contenido ante qué tipo de campo nos encontramos: solamente texto, una lista de la que elegimos entre unos valores concretos, un valor numérico, una fecha, etc.
Una vez hayamos dado todos los datos y pulsemos el botón OK, Glossary Converter terminará la conversión y veremos un archivo SDLTB con el mismo nombre y en la misma carpeta que el XLSX usado como archivo de origen. Si tenemos MultiTerm instalado, podemos mirar cómo ha quedado la base.
Ahora que disponemos de una base terminológica en Studio, ya podemos vincularla a un proyecto, para lo cual tan solo hay que abrir la ventana Configuración del proyecto, ir a Combinaciones de idiomas > Bases de datos terminológicas y pulsar el botón Utilizar > Base de datos terminológica MultiTerm basada en archivo. Después solo queda navegar hasta la carpeta correspondiente y seleccionar el archivo SDLTB.
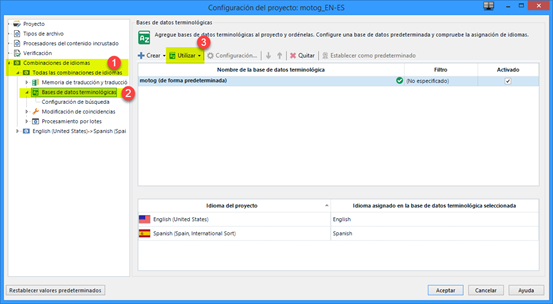
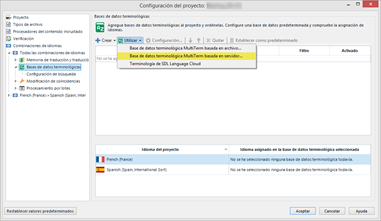
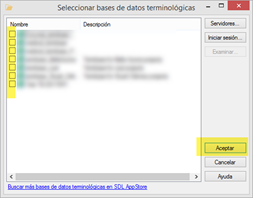
En algunos proyectos, usaremos bases terminológicas de servidor (Groupshare) en vez de locales. Para ello, en Configuración del proyecto, iremos a Combinaciones de idiomas > Bases de datos terminológicas y pulsaremos el botón Utilizar > Base de datos terminológica MultiTerm basada en servidor.
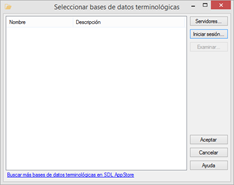
En el caso de que no hayamos añadido todavía el servidor en concreto, pulsaremos el botón Servidores.
Cuando aparezca la siguiente ventana, haremos clic en Agregar y pondremos los datos necesarios (dirección, usuario y contraseña) según corresponda.
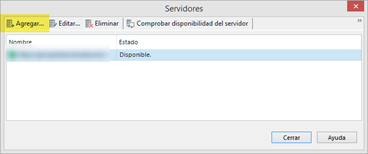
Ahora ya podremos pulsa en Iniciar sesión. Solo queda buscar la base terminológica correspondiente, marcar la casilla situada a su izquierda y hacer clic en Aceptar.
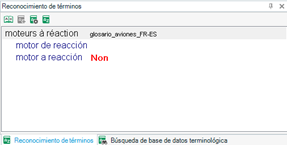
Una vez hayamos vinculado la base terminológica a Studio, los términos reconocidos aparecerán con un «tejado» rojo en el segmento de origen, así como en la ventana Reconocimiento de términos, como se observa en la siguiente imagen.

Asimismo, una de las ventajas de esta vinculación entre MultiTerm y Studio es que también podemos añadir términos a nuestra base terminológica a medida que vayamos traduciendo o revisando. Es tan sencillo como señalar el nuevo término y su traducción y pulsar Ctrl + F2 o bien Ctrl + Mayús. + F2 si queremos editar algún campo en el nuevo término. También podemos hacerlo accediendo al menú desplegable con el botón secundario del ratón, como se muestra en la siguiente captura de pantalla.
![]()
De forma similar a lo que ocurre en memoQ, la diferencia entre ambas opciones es que la primera permite que cambiemos los campos que queramos para ese nuevo par de términos, mientras que al elegir la segunda nos limitamos a añadir el par de términos directamente. Ya usemos una u otra opción, Studio mostrará el término y su equivalente cada vez que aparezca en el segmento de origen.
Aunque MultiTerm está integrado en Trados Studio, también es posible abrir las bases terminológicas, tanto locales como de servidor, en el primer programa. Para ello, abriremos MultiTerm y luego pulsaremos en el botón Abrir base de datos terminológica de la pestaña Inicio.
Si queremos abrir una base terminológica local en formato SDLTB y no está en la lista, pulsaremos el botón Examinar, navegaremos hasta la carpeta correspondiente para elegir ese archivo y pulsaremos en Aceptar.
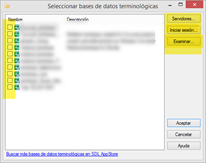
En el caso de que nuestra base terminológica esté en un servidor de Groupshare, tan solo tendremos que seguir los mismos pasos que se indican en la sección Bases terminológicas de Groupshare.
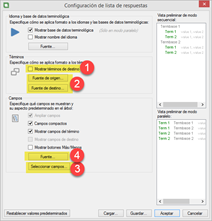
Por defecto, cuando Studio muestra términos en la ventana Reconocimiento de términos, no aparece ninguna información más relativa al término, tales como las notas, definición, contexto u otras (lo que dependerá de cada base terminológica en concreto). Conviene tener esta información a simple vista, en especial en campos como los términos prohibidos. Para ello, primero pulsaremos el botón Configuración de lista de aciertos, el tercero por la izquierda, tal y como se señala en la siguiente captura.
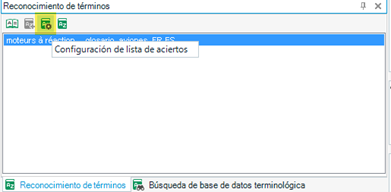
En la ventana que se abre a continuación, tendremos que marcar la casilla Mostrar términos de destino (1), y luego podremos configurar el formato con el que queremos que aparezcan los términos de cada idioma (2), como el tipo, el tamaño y el color de la fuente. Además, en Selección de campos (3) podemos señalar los campos que Studio debe mostrar siempre, así como configurar la fuente de dichos campos (4). Por ejemplo, el color rojo se podría usar para señalar los términos prohibidos o permitidos.
Esta captura de pantalla muestra el mismo término una vez se han ajustado todas las opciones:
Una de las opciones más interesantes de la terminología en Studio es aprovechar las bases terminológicas en nuestro trabajo, con el fin de que Studio nos avise si, por ejemplo, hemos dejado un término sin traducir o si hemos utilizado un término prohibido.
Como mínimo, tendremos que ir a Configuración del proyecto > Verificación > Verificador de terminología > Configuración de verificación y marcar la primera casilla. Si no hemos fijado un campo para los términos prohibidos y activamos la segunda casilla, Studio mostrará un símbolo de exclamación como advertencia de que la base no está bien configurada. También podemos cambiar el nivel de gravedad en cada una de las opciones según nuestras preferencias.
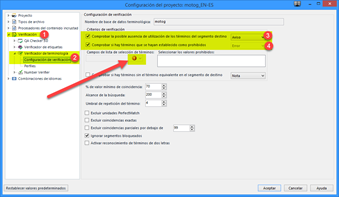
Una vez marcadas las opciones correspondientes, Studio nos mostrará un símbolo de aviso o de error en la columna central cuando confirmemos un segmento con posibles errores de terminología. Asimismo, si ponemos el cursor del ratón sobre dicho símbolo, podremos ver de qué tipo de aviso o error se trata, tal y como se ilustra en la siguiente captura de pantalla.
![]()
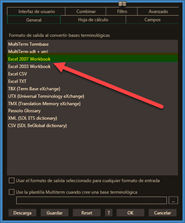
Al igual que con memoQ, también tenemos la opción de exportar nuestra base terminológica en formato SDLTB a un archivo XLSX que podemos guardar como copia de seguridad o bien compartir con otros compañeros que no utilicen Studio ni Multiterm. Para ello, tan solo tendremos que hacer el proceso de conversión inverso con Glossary Converter cambiando el formato de salida por Excel en configuración > General, como se muestra en esta imagen.
memoQ is a CAT tool designed by the Hungarian company Kilgray. Just like other tools as Trados Studio, the software works on a desktop application where the TM concordance and glossaries as well as the translatable files appear on the same window.
The bilingual file that is the basis of memoQ is a XLIFF variant, the MQXLIFF file format. It is still a XLIFF file at heart, but it contains some information that only memoQ can retrieve. This means the translation can be reused in another CAT tool supporting XLIFF files, but this information (such as versioning) will be lost.
Now we will see how to export and import bilingual files into memoQ, how to export target files and how to export our TMs into TMX as a backup or to share them with other users.
As translators and editors, we work with a wide variety of files, and there are some scenarios where we may deal with files that the software does not support by default (i.e. there is no filter available to import that type of file) or with other specific files which our client has modified. This would result in a file different from the standardized format, meaning we would need a custom file filter to import it properly into our CAT tool. Custom file filters are common when working with customized XML or XML-based files (such as XLIFF files), which can be modified as per the user’s needs.
Luckily for us, memoQ supports many other file formats and customizations and can import these specific files if there is an appropriate file filter for them. However, we need to add it to the existing filter list first. For that purpose, we need to press the Resource Console button in the top left corner of the main window of memoQ, as per the screenshot below. In other versions, we get to the same window by pressing the round memoQ button, then Resources and ultimately the Resource Console button.
Once in the Resource Console window, we need to press Filter configurations on the left side of the window and then we will see the filter list. Our next step is to import the new filter via the Import new button, as per the screenshot below.
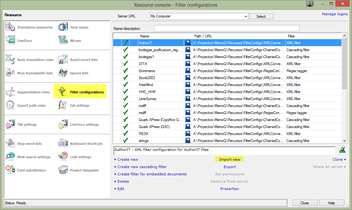
Then we only need to look for the MQRES file containing the filter provided by our client, select it and double click it to add it to the file filter list.
To add new files to an existing memoQ project using the new filter, we just need to go to the Translations pane, right click on the file list and select Import with options, as in the screenshot below.
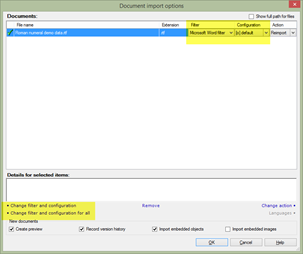
After selecting the files to Import, in the next window we can either choose Change filter configuration for all if all the new files need to be imported using the same filter, or just Change filter and configuration if several filters are needed in this import. Another way to do this is to choose the filter and configuration in the dropdown list for each file (please refer to the screenshot below).
If the import goes as planned, we will see that the new files are now in the file list for us to start translating them as suitable.
A diferencia de Studio, memoQ no suele tener problemas para extraer el contenido de las hojas de Excel incrustadas en archivos DOCX. Solo hay que seguir este proceso:
- Importar el DOCX usando la función Importar con opciones.
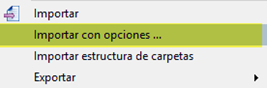
- En la ventana que aparecerá, hay que asegurarse de que la casilla Importar archivos incrustados esté marcada.
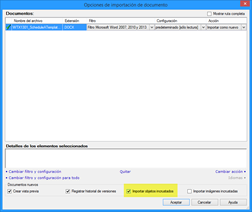
- Cuando termine la importación, veremos las hojas en la lista de archivos traducibles.
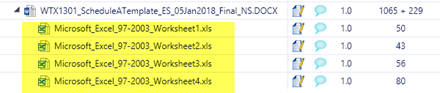
- Una vez hayamos terminado de traducir, lo único que queda es exportar los archivos siguiendo el proceso normal, abrir el archivo DOCX y actualizar los campos con F9, como se ha explicado antes.
Si todo lo anterior fallara, todavía nos queda extraer de forma manual las hojas de Excel de los archivos DOCX siguiendo este proceso:
- Hacemos una copia de seguridad de los archivos DOCX de origen.
- Como los archivos DOCX en realidad son un tipo de archivo comprimido, podemos cambiar la extensión de DOCX a ZIP para ver sus contenidos con un extractor de archivos comprimidos como WinRar.
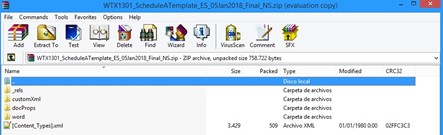
- Si navegamos a la carpeta word > embeddings, veremos las hojas de Excel incrustadas:

- Ahora podemos extraerlas e importarlas en la herramienta TAO de turno junto con el DOCX siguiendo el proceso normal.
- Una vez traducido todo, exportaremos los archivos desde la herramienta TAO.
- Ahora tenemos que hacer una copia de seguridad del archivo DOCX de destino y cambiar su extensión por ZIP.
- Después seleccionamos las hojas de Excel traducidas y las arrastramos y soltamos hacia la carpeta word > embeddings de este nuevo ZIP.
- Pulsamos pulsar el botón Aceptar cuando el programa nos pregunte si queremos actualizar el contenido del archivo ZIP y volvemos a cambiar la extensión a DOCX.
- Abrimos el DOCX en Word, comprobamos que no hay problemas, y seleccionamos todo el contenido del texto y pulsamos F9 para que se actualicen las hojas incrustadas con nuestras traducciones.
Suponiendo que ya tenemos creado el proyecto de memoQ y que hemos importado el archivo traducible, tendremos que seleccionarlo y después ir a Documentos > Exportar > Exportar archivos bilingües, como se ve en esta captura.
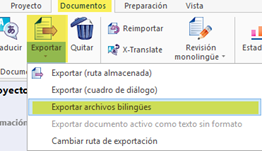
En la ventana que aparecerá, elegiremos RTF de dos columnas:
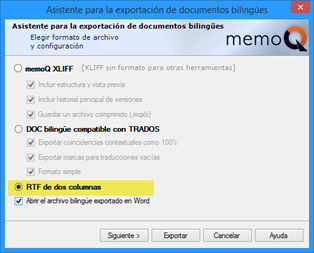
En el siguiente paso no es necesario que hagamos cambios, así que podemos pulsar el botón Exportar para que se cree el archivo RTF. El traductor tendrá que abrir el archivo RTF y traducir en la columna del idioma de destino, añadiendo comentarios en la columna correspondiente si es preciso.

Una vez haya terminado de traducir, tan solo habrá que guardar el archivo.
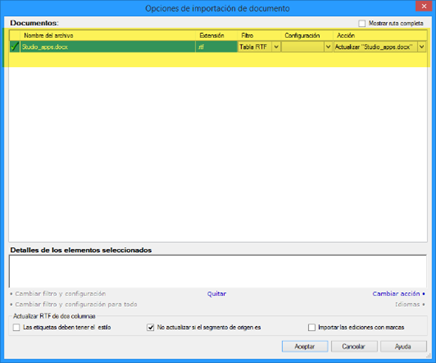
De vuelta en memoQ, tendremos que usar la función Importar > Importar con opciones Importar > Importar con opciones y seleccionar el archivo que hemos recibido del traductor.
Si todo va bien, memoQ nos indicará que el archivo es una actualización de otro que ya está en el proyecto, así que podemos pulsar Aceptar sin ningún problema.
Una vez que haya terminado el proceso de importación, memoQ nos mostrará un informe y ya podremos abrir el archivo para comprobar que todo ha funcionado correctamente.
Una vez comprobado, podremos enviar todos los segmentos a una memoria o exportar el archivo como MQXLIFF para tener una copia en formato bilingüe. Para tal fin, usaremos Exportar > Exportar archivos bilingües y desmarcaremos las tres casillas en la sección memoQ XLIFF, como se ve en la imagen.
Tras pulsar Exportar, ya tendremos el MQXLIFF con todas las traducciones.
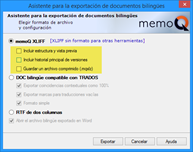
When we are working in a memoQ project and want to export a bilingual file (e.g., so we can proofread or QA it with another tool), we should go to the Translations Pane, select the applicable files, right click, and then choose Export bilingual. The export bilingual wizard will begin, as per the screenshot below. We will focus on the memoQ XLIFF options.
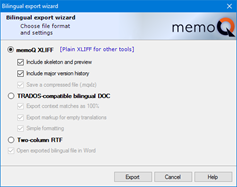
You will see that there are three checkboxes checked by default. If we uncheck them all or click Plain XLIFF for other tools, memoQ will create a MQXLIFF file which can be opened in other CAT tools such as Trados Studio. However, if we receive that same MQXLZ file from another linguist, we will NOT be able to create the target file, as memoQ cannot retrieve the information relating to the source formatting.
If we want to avoid this issue and send a bilingual file to another linguist that can be exported to a target file, we just need to keep those checkboxes checked, thus obtaining a MQXLZ file, which is nothing rather than a zipped file that is optimized for memoQ.
If we leave the first checkbox (Include skeleton and preview) checked, memoQ will include a skeleton.xml file that, in a nutshell, contains the formatting information relating to the source file. If we import that MQXLZ file into a memoQ project, memoQ will retrieve the information from that skeleton.xml file, and so we will be able to create the target file (unless there are tag-related or other critical errors). Some translation agencies may uncheck this box when sending bilingual files to external resources for confidentiality reasons to keep them from creating the target file.
If we have created a project and processed the source file directly in memoQ, we can export the target files by selecting them in the Translations pane and choosing the Export (Dialog) option, as per the screenshot below. The target files will be then saved to the desired folder.

Considering all the above, does this mean that we will not be able to create the target file if we just have a MQXLIFF file? If we have the source file, we still could do so with any of these two options below:
- By creating a new memoQ project with the same language pair and filter as originally done by the first linguist. We would just to create a new TM and update it with all the segments from the file (see section 6. 7) and then pretranslate it, fix any possible errors and export the target files as per the normal process.
- If we are working with huge files and want to save some time, there is an alternative to pretranslation. First, we would memoQ tries to import as a new file (instead than as an updated file) a bilingual updated file need to create a new memoQ project with the same language pair and filter as original done by the first linguist. Immediately after uploading the source files, we will need to export them as plain MQXLIFF files (i.e. by unchecking the three checkboxes on the Export wizard). Then, if we use an application such as Beyond Compare, we can compare the new, empty MQXLIFF against the translated MQXLIFF, copy the line with the memoQ file ID from the former to the latter and save the latter and finally import it into memoQ. If we have proceeded correctly, memoQ will tell us that the MQXLIFF is an update of a project file. This trick can be useful as well when which was exported from the same project.
If we are unsure if the MQXLZ file contains a skeleton file, we can check it by renaming the file to .zip so we can open it using WinRAR or another file archiver. Once checked, we just need to import it into an existing memoQ project with the same language pair, and once the process is complete, select either the Export (dialog) or Export (saved path) options. Please note that, as per the screenshot below, if the file does not contain a skeleton file, the export options will be greyed out and we will not be able to export it.

If we need to create a TMX file using memoQ, we need to proceed as follows:
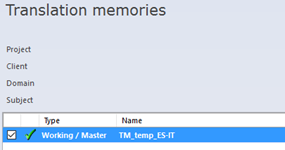
If we have not do so yet, please create a memoQ project with the appropriate language pair and make sure all the applicable translatable or bilingual files have been imported into the project. In the Translation Memories pane, either select an existing TM or create a new, blank TM with the memoQ proprietary MEMOQTM file format (this way we will be certain it does only contain the segments from this project) and make sure it is linked to the project as Master TM, like in the screenshot below.
Go to the Preparation tab and click Confirm and Update Rows (please check the screenshot below) or alternatively press Ctrl + Shift + U. Then we need to choose the files and segments to be saved into the TM (or we can select Project from the Scope options). Then we click OK and wait until the process is done.

Lastly, we just need to select the applicable TM, right click and select Export to TMX to save a TMX copy of our translation memory to desired folder.
La principal diferencia de memoQ con respecto a Studio es el que primero permite separar las repeticiones de las no repeticiones de un modo mucho más cómodo y directo que con Studio. La clave, en este caso, se encuentra en las vistas de memoQ, que servirán de base para encarar este tipo de proyectos. La siguiente entrada del blog Melodía de traducción cuenta con más información sobre las vistas:
Suponiendo que ya tenemos creado el proyecto de memoQ y que hemos importado los archivos traducibles, tendremos que crear la primera vista (la de repeticiones). Para tal fin, solo hay que seleccionar los archivos, hacer clic con el botón secundario del ratón y elegir Crear vista en el menú desplegable que aparecerá, tal y como se ve en esta captura.
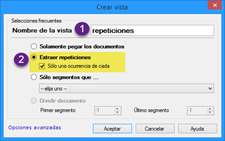
Ahora es el turno de dar un nombre (lo más descriptivo posible a la vista). Después tenemos que elegir el criterio Extraer repeticiones. Como pretendemos que el número de palabras para traducir sea todo lo reducido que se pueda, marcaremos la casilla Sólo una ocurrencia de cada.
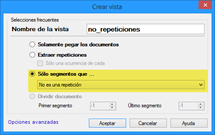
En el siguiente paso, crearemos otra vista (de no repeticiones), para lo que utilizaremos el criterio Sólo segmentos que > No es una repetición, como se observa en esta captura.
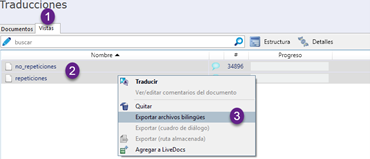
Tras crear ambas vistas, ya podremos exportarlas como archivos bilingües para que los traductores y revisores trabajen en ellas. Para ello, iremos a la pestaña Vistas, las seleccionaremos, haremos clic con el botón secundario del ratón y elegiremos la opción Exportar archivos bilingües, como en esta imagen.
Con el fin de reducir al mínimo los errores por incompatibilidad entre herramientas TAO, el formato más recomendable es memoQ XLIFF con las tres casillas desmarcadas.
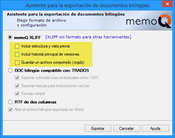
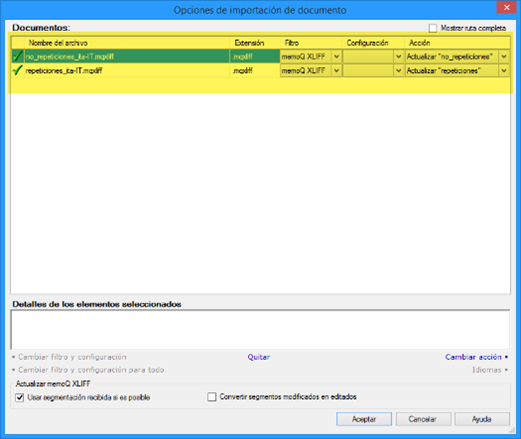
Cuando el traductor o el revisor hayan terminado su trabajo, recurriremos a la función Importar > Importar con opciones y seleccionaremos aquellos archivos MQXLIFF que hayamos recibido.
Si todo va bien, memoQ nos avisará de que los archivos son actualizaciones de otros existentes en el proyecto. Ahora solo queda pulsar Aceptar y esperar a que termine la importación.
Si memoQ no detecta que estos archivos son actualizaciones, conviene intentar solucionar el problema siguiendo los pasos de esta entrada del blog Melodía de traducción:
https://melodiadetraduccion.com/problemas-al-importar-archivos-mqxliff-actualizados-en-memoq/
Una vez que haya terminado el proceso de importación, memoQ nos mostrará un informe y ya podremos abrir los archivos para comprobar que todo ha funcionado correctamente.
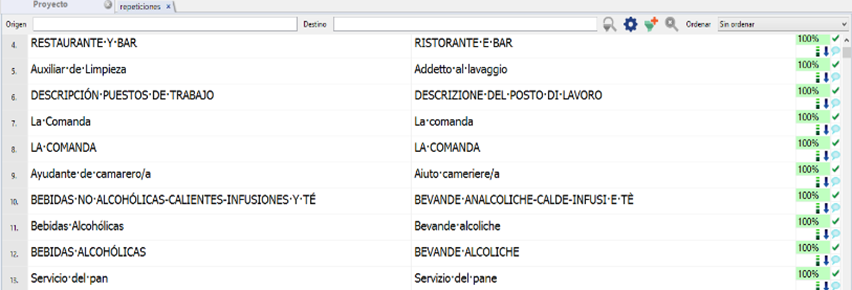
Tras asegurarnos de que ambas vistas están traducidas, el siguiente paso consiste en enviar las traducciones a una memoria y después pretraducir los archivos principales (pues solamente extrajimos una aparición de cada segmento repetido).
Aunque no es obligatorio, lo recomendable es crear una memoria vacía en el panel Memorias de traducción y vincularla al proyecto como memoria maestra para asegurarnos de que los archivos principales no se «contaminan» con traducciones de una memoria ajena.
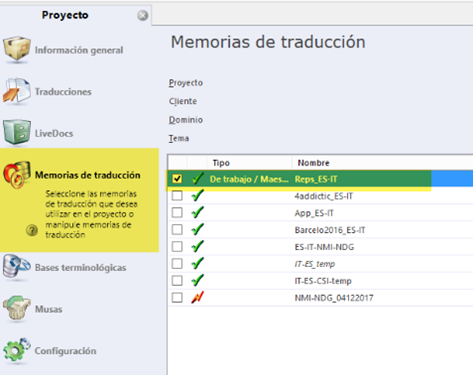
La siguiente etapa del proceso es enviar las traducciones de las vistas a la memoria. Para ello, seleccionaremos las vistas e iremos a la pestaña Preparación. Después pulsaremos el botón Confirmar y actualizar, tal y como se ve en la siguiente captura.

En la ventana que aparecerá, marcaremos todas las casillas correspondientes según el proyecto y seleccionaremos la opción Actualizar memoria de trabajo/maestra. Tras pulsar Aceptar, todos los segmentos de las vistas que cumplan los criterios serán enviados a la memoria.
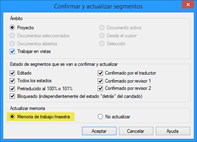
Ahora que todos los segmentos están en la memoria, seleccionaremos los archivos principales y pulsaremos el botón Pretraducir dentro de la pestaña Preparación.

Aparecerá una nueva ventana en la que escogeremos Coincidencia exacta de memoria (100 %). Después marcaremos la opción homónima en la pestaña Confirmar/bloquear, gracias a lo cual todos los segmentos que sean 100 % ahora ya aparecerán como traducidos y confirmados.
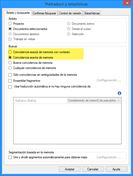
Tras pulsar Aceptar, repetiremos el proceso, salvo que con la opción Coincidencia exacta de memoria con contexto (también conocidos como 101 %). Si todo funciona como debe, ahora los archivos principales deberían estar completamente traducidos.
Como punto final a este proceso, ya podemos exportar nuestros archivos principales traducidos siguiendo el procedimiento habitual. Solo hay que seleccionar los archivos, hacer clic con el botón secundario del ratón e ir a Exportar > Exportar (cuadro de diálogo).

Entonces aparecerá una ventana en la que tendremos que indicar a memoQ la carpeta donde queremos guardar los archivos de destino. Una vez terminado el proceso, ya será posible abrir los archivos traducidos con el programa correspondiente, hacer las comprobaciones oportunas y enviárselos de vuelta al cliente.
When working in memoQ projects as a translator or as an outsourcer, it is important that we know about the Homogeneity parameter specifically used in memoQ when calculating the word count of that project. We can enable or disable homogeneity as applicable in the Statistics window, as per the screenshot below.
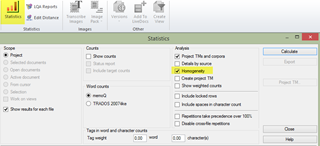
Enabling the homogeneity parameter intends to obtain a weighted word count closer to the actual number of words we will really translate, as homogeneity takes into the account the similarities in the internal structure, both in the same file and throughout all the files within a project.
When translating a file, we first will add a no match segment to a TM. As a result, if we come across later in that or project with the same segment or almost the exact same segment, it will no longer be a no-match segment, but rather a 100% or 95-99% match, as we can retrieve our translation from the TM. CAT tools would normally consider these two segments as 2 no-match segments rather than a no-match and a 100% match or repetition, as it should be.
If we apply the same logic to all segments and all files within the project, it is easy to see that in some scenarios there may be a great gap between the word count calculated via the usual process (i.e., non-homogeneity in memoQ) and the word count obtained using homogeneity. In a nutshell, homogeneity aims to compensate this difference in word count by analyzing the project internal similarities.
Technically speaking, memoQ processes each segment by scanning the files in alphabetical order and adds it to a temporal TM which memoQ uses to lookup for every segment processed subsequently, thus simulating it was already translated. This gives more realistic values, simulating the translation memory results a translator gets while working: if the translator actually translates the first segment, and goes to the second segment that is 80% similar, he also gets a 80% match.
memoQ allows us to disable homogeneity when calculating the word count of a project, as this logic does not apply if the project is divided among several translators. For example, there may be two instances of a segment in two different files of the project. If these two files go to two different translators working at the same time, this segment will be new for both (unless one file is translated after the other and the second translator uses the TM from the first translator containing that segment).
El objetivo de esta sección es servir de introducción a la extracción de terminología usando memoQ en aquellos proyectos donde se requiera una gran precisión en la traducción de los términos. Por ejemplo, es un recurso útil en proyectos a largo plazo y que versen sobre un área de especialidad en concreto, pues permite obtener un glosario inicial antes incluso de comenzar con la traducción y así contribuir a la coherencia terminológica en nuestro trabajo. Asimismo, dicho glosario se puede compartir fácilmente con nuestro cliente, quien puede asesorarnos sobre la traducción de cada término según el caso.
Este manual no pretende ser exhaustivo ni analizar todas las opciones que ofrece memoQ, sino que anima al usuario a descubrir cuales tiene que emplear según el proyecto o sus necesidades concretas. Como aclaración, cabe decir que la gran alternativa a memoQ, Trados Studio, también dispone de modos de extraer términos, pero para ello es necesario instalar complementos. Dado que memoQ es más cómodo porque cuenta con un módulo de extracción de términos ya incluido en el programa, para el propósito de este manual nos centraremos en esta última herramienta TAO. No obstante, la sección 6.10.4 de este manual la dedicamos al uso en Studio de bases terminológicas creadas con memoQ.
Con el fin de explicar mejor cómo funciona la extracción de términos en memoQ, supongamos que nos toca trabajar en un proyecto a largo plazo en el que traduciremos unos archivos DOCX de origen y una memoria de traducción proporcionada por el cliente. Entonces emplearemos todos esos archivos como base para la extracción de términos y su importación en una base terminológica. Por último, daremos unos breves apuntes sobre la gestión de bases terminológicas y cómo añadir términos mientras traducimos.
Suponiendo que ya hemos creado el proyecto en memoQ y añadido la memoria facilitada por el cliente, vamos a empezar una sesión de extracción de términos, para lo cual pulsaremos el botón Extraer términos situado en la pestaña Preparación de la cinta de opciones de memoQ.
![]()
Entonces se abrirá una primera ventana donde, aparte del nombre de la sesión, podremos cambiar las siguientes opciones según los idiomas, el área temática, etc.
- Los archivos a partir de los cuales memoQ extraerá la terminología: pueden ser una o más memorias o archivos de origen o un corpus (LiveDocs).
- El número mínimo de apariciones de un posible término para que memoQ lo considere candidato, así como el número máximo de palabras que pueden formarlo, así como el mínimo de caracteres que debe haber en un término de una sola palabra.
- Por último, podremos configurar la lista de palabras que memoQ no tendrá en cuenta cuando busque términos (preposiciones, conjunciones, etc.), bien añadiendo esas palabras o cargando las listas que memoQ trae por defecto o la nuestra propia.
Además, podemos indicar a memoQ si queremos que descarte la palabra correspondiente si aparece al principio del posible término, en el medio o al final respectivamente.
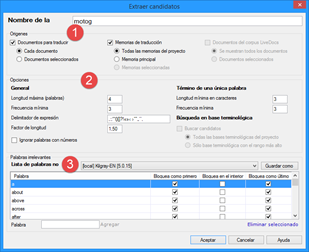
Tras pulsar el botón Aceptar, memoQ hará la extracción previa y nos llevará a la pestaña Extracción de términos una vez concluido el proceso, como se ve en la siguiente captura de pantalla.
A continuación, explicamos las funciones más destacadas:
- Aceptar como término: añade el término marcado a la lista de términos aceptados, que son los que se añadirán a la base terminológica al final del proceso.
- Colocar término: cambia el estado del término a Quitado y lo desplaza al final de la lista cuando reordenamos la lista de posibles términos.
- Unir/dividir candidatos: une varios candidatos a términos en uno solo o separa un candidato en varios, respectivamente.
- Prefijo unir & ocultar: busca términos con el mismo prefijo que el seleccionado, por lo que debe contener la barra vertical (|), cuyo significado explicamos más adelante.
- Ocultar/mostrar el más corto: sirve para ocultar o mostrar los términos incluidos dentro de un término candidato. Por ejemplo, si lo usamos con perro guía y tenemos perro y guía en la lista de candidatos, estos dos últimos quedarán ocultos.
- Agregar como palabra irrelevante: añade el posible a la lista de palabras que no se tienen en cuenta para encontrar términos.
- Reiniciar sesión: esta función elimina la lista de candidatos y la vuelve a crear, con lo que se pierden los cambios que se hayan hecho.
- Exportar a la base terminológica: añade los términos candidatos aceptados a la base terminológica que escojamos. Con ello se puede dar por terminada la sesión de extracción de terminología.
memoQ ordena los candidatos según un criterio que denomina «valor de confianza» (es decir, el valor de certeza de que ese candidato es realmente un término), pero podemos hacer lo propio según el número de apariciones, la extensión o según hayamos rechazado o aceptado el candidato.
Dado que estas palabras no son términos confirmados, sino candidatas para ser términos, podemos empezar marcando las que queremos descartar, bien sea de una en una o en bloque, haciendo clic con el botón secundario del ratón y luego pulsando la opción Colocar término [sic, debería ser «Eliminar término»], como se observa en la captura de pantalla.
También podemos añadir esas palabras a la lista de palabras no significativas (es decir, las que no se tendrán en cuenta a la hora de buscar candidatos a términos), lo que puede ser muy útil en el caso de adverbios, verbos, conjunciones o contracciones.
Cuando nos encontremos con una palabra que queremos añadir como término, en el panel inferior izquierdo veremos algunos ejemplos donde aparece dicha palabra señalada en color naranja, ya provengan de los archivos de origen, de la memoria o del corpus.
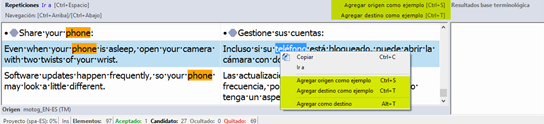
En este panel podemos acceder con el botón secundario del ratón a varias opciones, como añadir el segmento de origen o de destino como ejemplos de uso que será posible consultar cuando el término forme parte de una base terminológica. Además, si tenemos un ejemplo en el idioma de destino, podemos señalar el equivalente del término en esa lengua y añadirlo. Entonces veremos el candidato con toda la información que hemos añadido y lo podremos aceptar como término. El valor de la columna Estado cambiará a «Aceptado» y pasará a tener el fondo de color verde, tal y como se ve en la siguiente captura.
![]()
Ahora solo nos quedará repetir el proceso con todos los candidatos hasta quedarnos únicamente con aquellos que nos interesa tener en una base terminológica.
Cuando hayamos terminado de elegir los términos, podemos enviarlos a la base terminológica vinculada al proyecto desde el botón Exportar a la base terminológica situado en la cinta de opciones. Si no tenemos ninguna base vinculada, memoQ mostrará un mensaje de error.

En la ventana que aparecerá, añadiremos la información vinculante a los términos según queramos y, en caso, podemos enviar los candidatos desmarcados a la lista de palabras irrelevantes con el fin de que memoQ las tenga en cuenta en futuras sesiones de extracción de términos.
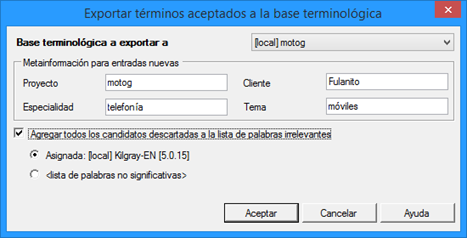
Otra opción que ofrece memoQ es la de exportar los candidatos aceptados como términos a un archivo de Excel en formato XLSX. De esta forma, podemos tener una copia para, por ejemplo, compartirla con traductores y revisores que no usen memoQ. Esa copia también se puede enviar al cliente, con el propósito de que nos haga correcciones o sugerencias con respecto a esos términos.

Tras pulsar el botón Exportar a Excel, obtendremos un archivo en formato XLSX similar al que se muestra en la siguiente captura de pantalla.
En la siguiente sección veremos cómo utilizar memoQ para añadir términos a una base terminológica mientras traducimos o revisamos, así como para editar una base terminológica para optimizar los resultados y para aprender a exportar o importar términos a modo de intercambio o de copia de seguridad.
Cuando usemos durante una traducción la base terminológica que hemos actualizado con los términos durante la sesión descrita en la sección anterior, los términos que reconozca memoQ aparecerán destacados en azul. Como cabría esperar, también podemos añadir nuevos términos sobre la marcha con el fin de completar y perfeccionar nuestra base terminológica.
Si seleccionamos el término en el idioma de origen y su equivalente en la lengua de destino y hacemos clic con el botón secundario del ratón, podremos elegir entre dos opciones, Adición rápida de término (Ctrl + Q) y Agregar término (Ctrl + E), según se muestra en la siguiente imagen.
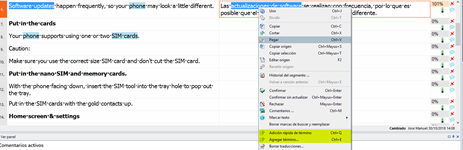
La diferencia entre ambas opciones radica en que la segunda opción permite, aparte de añadir el par de términos, modificar los campos correspondientes (temática, área de especialidad, cliente, proyecto, etc.), mientras que la forma rápida sirve para agregar el par de términos sin hacer más cambios.
Si queremos cambiar parámetros de la base terminológica, tendremos que ir al panel Bases terminológicas, elegir la base que corresponda, hacer clic con el botón secundario del ratón y pulsar Editar, o bien pulsar el mismo botón situado en la sección inferior de la ventana.
Entonces nos encontraremos ante el listado de términos. Nos centraremos en el panel inferior, en el cual figuran la mayoría de las opciones. Como se ve en la captura, se divide a su vez en varios paneles, uno por cada idioma más el general (campos que pertenecen al término en sí mismo y no a un idioma concreto).
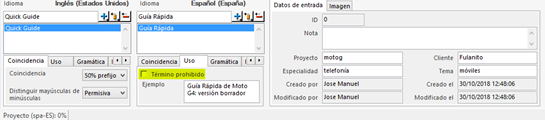
En el panel general, la pestaña Datos de entrada sirve para cambiar algunos campos relacionados con el término, mientras que Imagen permite importar una imagen del término para que se use como referencia.
En los paneles de los idiomas, podemos cambiar, añadir o quitar términos, así como indicar su categoría gramatical y su definición. Además, si tenemos una lista de términos prohibidos (usados en otras variantes del idioma, descartados por el cliente, etc.), podemos marcar la casilla resaltada en amarillo para que en el control de calidad se nos indique si hemos usado algún término prohibido por error.
Asimismo, en la pestaña Coincidencia de cada idioma, podemos decidir si queremos que memoQ haga distinciones entre mayúsculas o minúsculas (muy útil si el término es un acrónimo o un código alfanumérico). Por ejemplo, si tenemos la abreviatura inglesa IT en un glosario, memoQ no mostrará el término si aparece como it, pues equivale al pronombre inglés y podría dar lugar a errores de traducción.
También es posible cambiar el tipo de coincidencia por una de las opciones siguientes (lo que puede resultar casi indispensable según las características de cada idioma en concreto).
- Coincidencia parcial: memoQ encontrará formas compuestas con sufijos o prefijos del término, como ocurre en idiomas como el alemán. Por ejemplo, si la base terminológica contiene Festplatte y speicher, memoQ señalará el término Festplattenspeicherplatz.
- 50 % prefijo: es la opción que aparece activada de forma predeterminada. Permite ligeros cambios en el término, de forma que memoQ detectará proyectos si proyecto está en la base terminológica.
- Exacta: busca el término de la forma exacta en que aparece en la base terminológica. Siguiendo el ejemplo anterior, memoQ encontraría proyecto pero no proyectos.
- Personalizado: este valor es útil si usamos caracteres comodín al añadir términos a la base terminológica. La raya vertical (|) indica el comienzo de una parte variable de un término (es decir, esa parte puede o puede no aparecer), mientras que el asterisco (*) señala que cualquier conjunto de caracteres puede ir detrás el último carácter. Por ejemplo, el término gesto| de proyect| detectará tanto gestor de proyecto como gestoras de proyectos.
Desde esta misma ventana donde hemos trabajado en el apartado anterior podemos exportar o importar nuevos términos desde los botones correspondientes de la cinta de opciones.
- Importación de términos
Al igual que ocurre con las memorias de traducción, podemos aprovechar bases de datos terminológicas procedentes de otros programas o profesionales e importarlas en nuestra propia base terminológica. memoQ puede importar bases en formato CSV, TSV, TMX, XLS(X), XML de Multiterm y TBX (el estándar para intercambio de bases de datos terminológicas). Al pulsar el botón Importar, memoQ abrirá una ventana del explorador desde la que tenemos elegir la fuente de los nuevos términos (TMX, CSV, XLSX, etc.). Entonces aparecerá la siguiente ventana:
Ahora tenemos qué indicar en qué columnas están los términos de cada idioma bajando por la lista en Campos y marcado la casilla Importar como término y elegir el idioma que corresponda. Si queremos importar otros campos, usaremos las opciones Importar como definición o Importar como otro campo.
Si queremos omitir alguno de los campos, escogeremos la opción No importar. Así mismo, como en este archivo de Excel en concreto la cabecera de cada columna es la descripción de ese campo, activaremos la casilla La primera fila contiene nombres de campo para que no se incluya esa fila al importar. Tras pulsar Aceptar, memoQ importará los términos correspondientes.
- Exportación de términos
Cuando pulsemos el botón Exportar, memoQ mostrará una ventana como la de la siguiente captura, en la cual podemos decidir el formato de archivo al que se exportará la base terminológica, así como la codificación y los campos, en el caso de queramos omitir alguno de ellos.
Entonces obtendremos un archivo que podremos usar simplemente como copia de seguridad o bien para compartirlo con nuestro cliente o con un traductor o revisor que no use memoQ.
En el caso de queramos usar una base terminológica ya existente en otro proyecto de memoQ, tan solo tendremos que ir al panel Bases terminológicas dentro de la sección Proyecto, elegir la base que corresponda, hacer clic con el botón secundario y pulsar en Usar en el proyecto, como se muestra en la captura de pantalla y repetir el paso las veces necesarias si queremos añadir varias bases terminológicas. Si la base no figura en la lista, podemos recuperarla mediante la opción Registrar local.
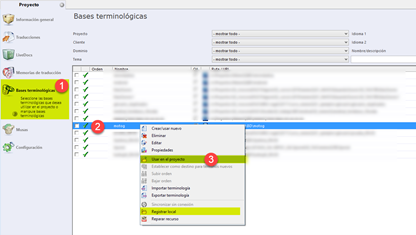
También podemos añadir bases terminológicas desde fuera de un proyecto mediante la Consola de recursos. Este podría ser el caso de alguna de las bases terminológicas existentes en OwnCloud, comprimidas en formato ZIP para ahorrar espacio. En esas situaciones, seguiremos estos pasos (señalados con números en la siguiente captura de pantalla):
- Descomprimir el archivo ZIP en otra carpeta del disco duro (fuera de OwnCloud, con el fin de evitar problemas de sincronización).
- Abrir memoQ y luego la Consola de recursos, situada en la esquina superior izquierda (1).
- Abrir Bases terminológicas (2).
- Pulsar en Registrar local (3), navegar hasta la carpeta del paso 1 y hacer doble clic sobre el archivo mtb. Ahora la base aparecerá en la lista.
- Seleccionar la base recién añadida y pulsar en Editar (4) para ver los términos y poder hacer todo lo explicado en la sección 10.3.
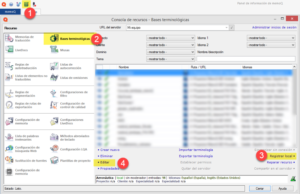
De esta forma,se importaría la base completa, con todos los idiomas, por lo que lo recomendable es usar el archivo XLSX que también hay en Sharepoint / Owncloud, borrar todas las columnas menos la de los idiomas del proyecto y entonces sí se puede importar a una base terminológica ya existente/creada en el ordenador.
Como nota muy importante, es necesario recordar añadir la barra vertical para indicar los sinónimos a la hora de importar dicho XLSX en memoQ: