MTPE para PSI [PMM]
1. Introducción
Ver apartado MTPE del manual de PSI de la Okopedia para conocer las características de este tipo de trabajos para este cliente.
Para el siguiente ejemplo, elegimos la solicitud de MTPE por parte de PSI de un documento en PDF.
Al cliente se le dijo que además del motor de traducción automática, se tendría en cuenta su TM, por lo que a veces en sus solicitudes nos indican que quieren MTPE + TM. Es el mismo proceso ya que para PSI siempre se va a hacer así.
2. Presupuesto
Para el presupuesto, pasaremos el documento por el OCR y lo analizaremos con la memoria de traducción correspondiente como para cualquier proyecto estándar del cliente. Por el momento, no es necesario incluir ningún motor de traducción automática.
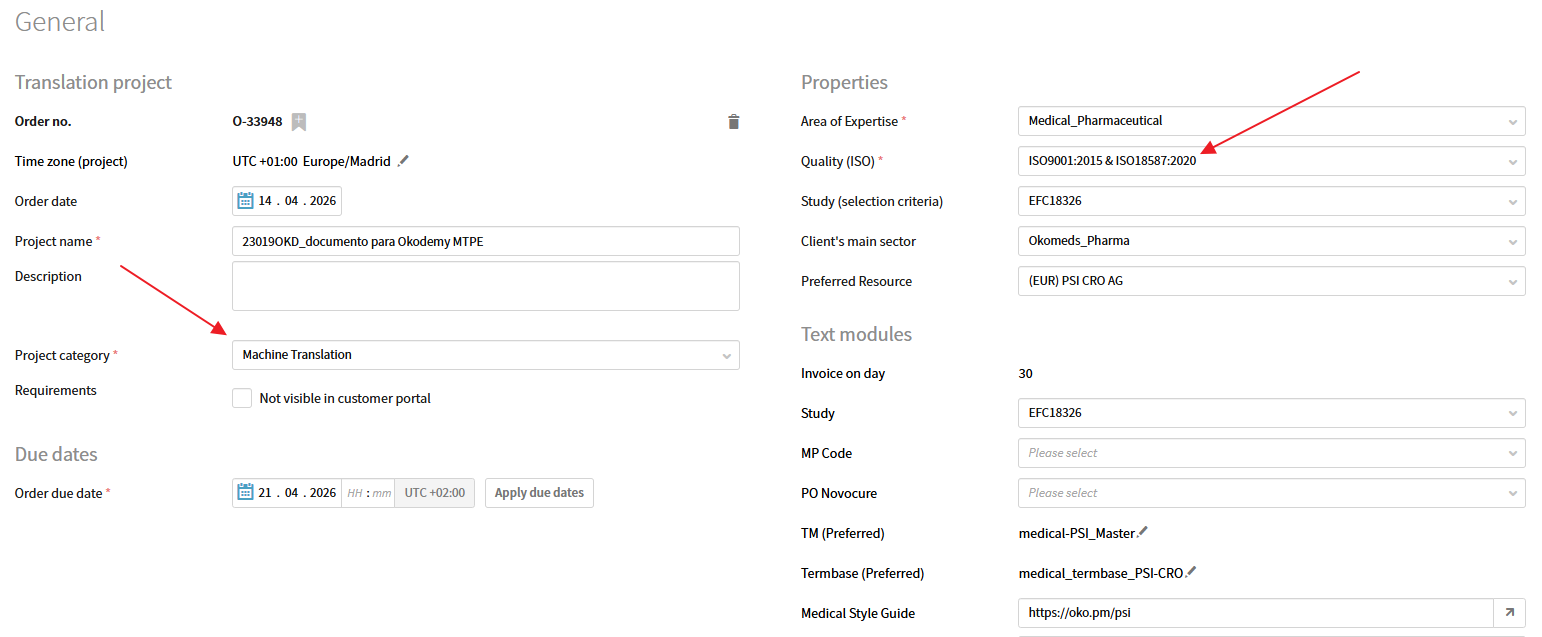
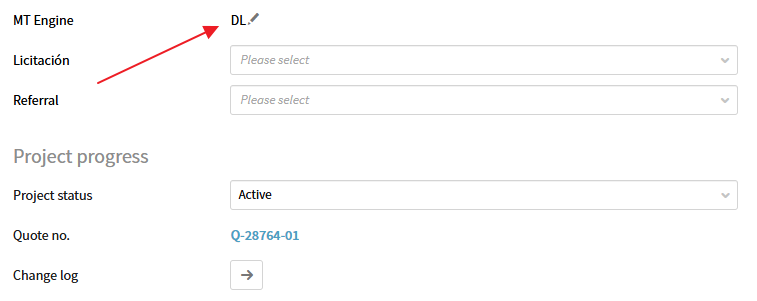
En Plunet, lo particular de estos trabajos será que seleccionaremos Machine Translation en Project Category, la ISO9001:2015 & ISO18587:2020 en Quality (ISO) y DL en MT engine.
Seleccionaremos la combinación de idiomas y subiremos los documentos como habitualmente pero elegiremos el listado de tarifas de MTPE de PSI.
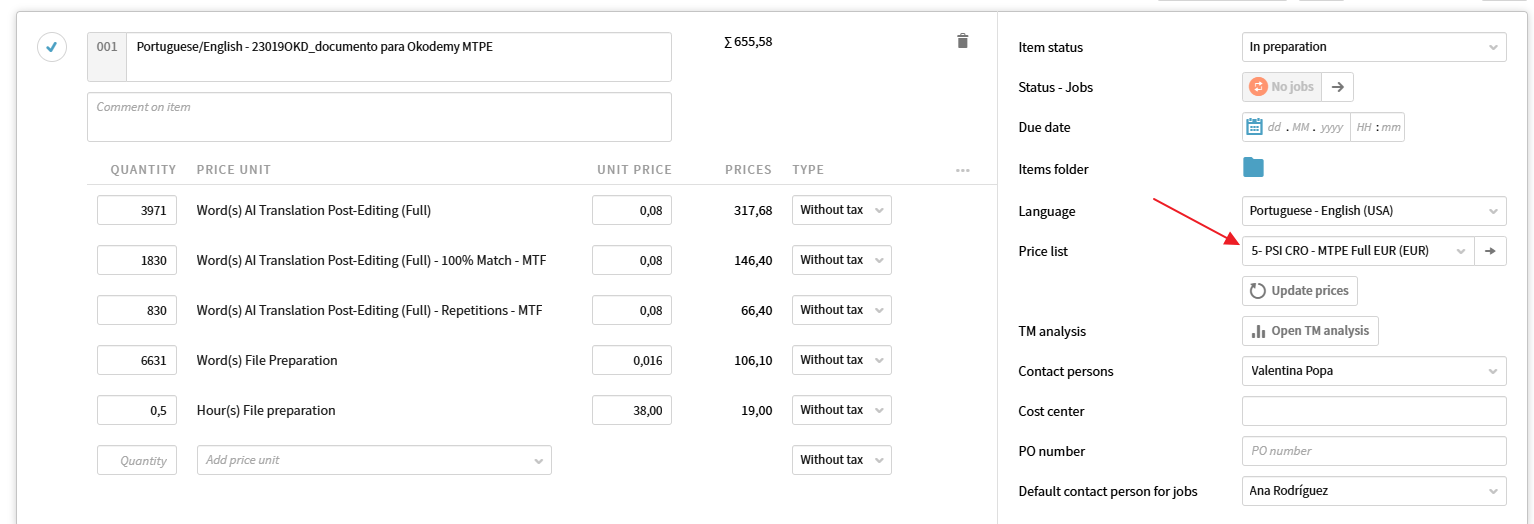
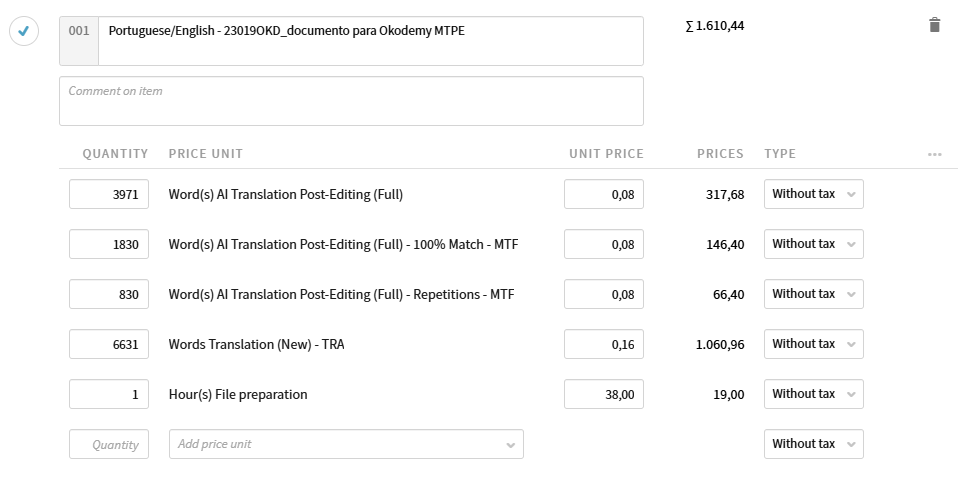
Al aplicar el análisis, saldrán los recuentos de palabras para los diferentes rangos con la tarifa de MTPE. Nota: el importe para los diferentes rangos es el mismo.
Además, añadiremos el cargo de Word(s) File Preparation (recordemos que es un pdf) y el cargo de Hour(s) File Preparation porque para PSI cualquier trabajo de MTPE requiere un cargo de preparación de archivos de 7 minutos por documento redondeando en cuartos de hora y con un mínimo de 0,5 h.
Le daríamos a crear el presupuesto como habitualmente y ya estaría.
3. Creación de proyecto
Una vez el cliente nos ha confirmado el presupuesto y hemos creado el documento en word limpio, creamos el proyecto en Trados añadiendo la TM, el motor de traducción y la termbase:
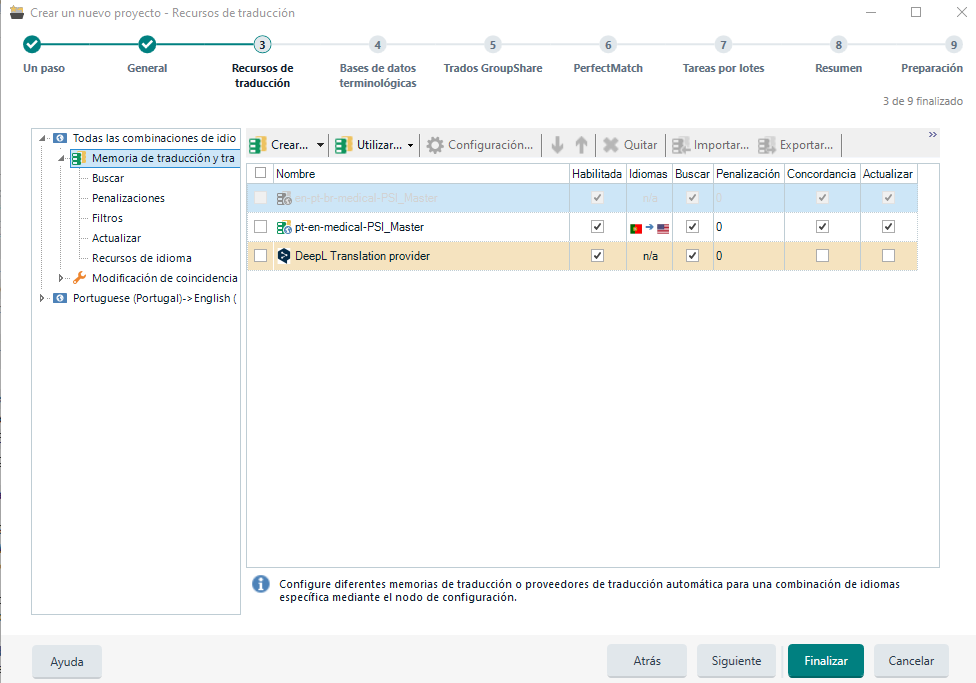
Le damos varias veces a Siguiente hasta llegar a la pestaña de «Tareas por lotes» donde pretraduciremos el archivo con la TM y no se tendrá en cuenta el motor de traducción automática. Para ello cambiaremos el «Valor mínimo de coincidencia» al 80 y marcaremos «Dejar segmento de destino vacío»:
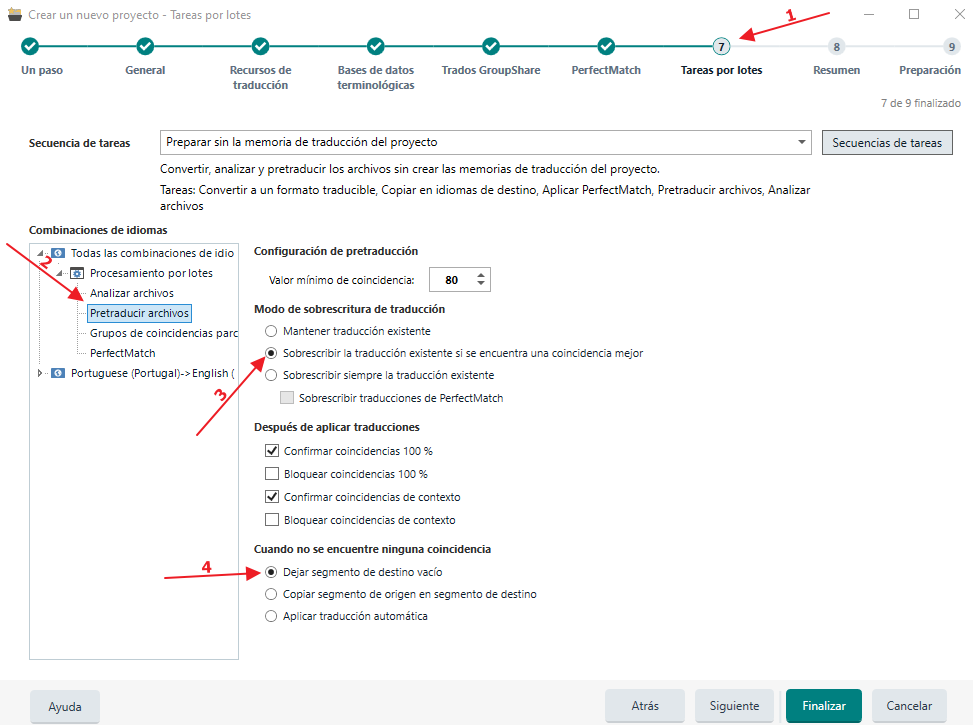
Le damos a «Finalizar» y se crea el proyecto.
Abrimos el sdlxliff para ver que ha quedado correcto, es decir, que no hay segmentos traducidos con el motor de traducción sino que los que no tenían coincidencias se han quedado vacios:
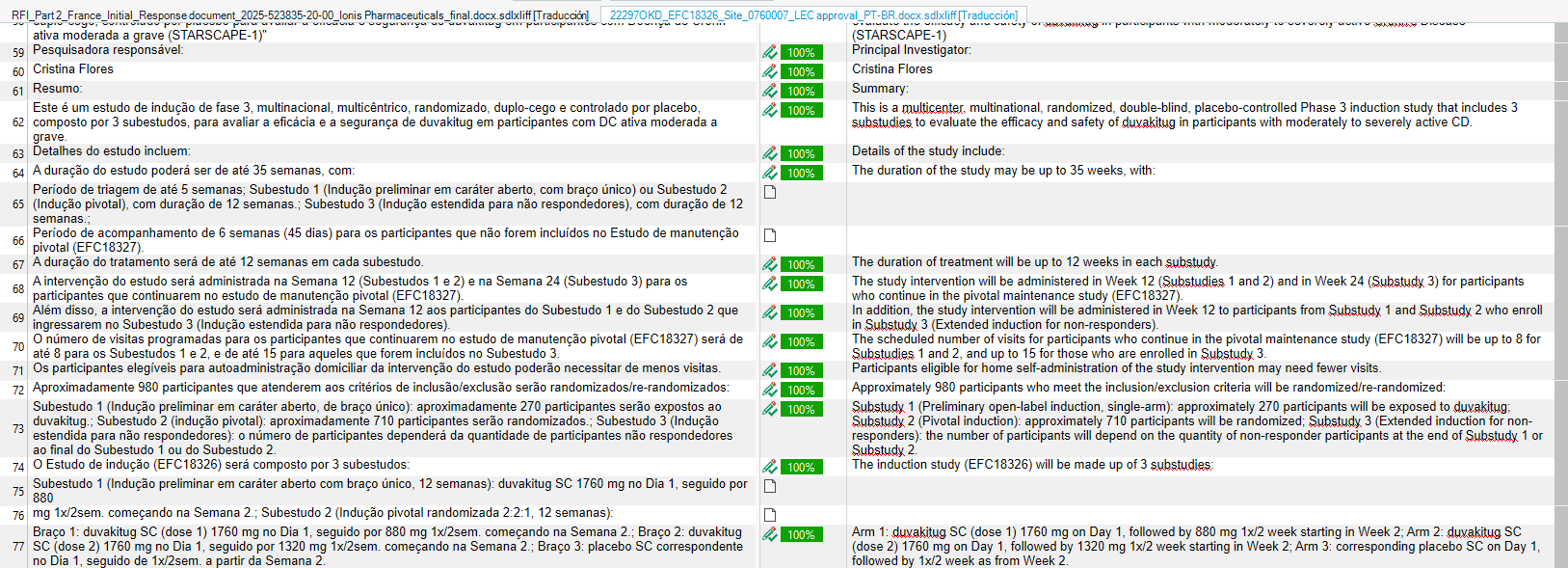
Ahora ya sí, hacemos click en «Tareas por lotes» y pretraducimos el documento aplicando el motor de traducción. Para ello, seleccionamos «Pretraducir archivos» y en «Configuración» cambiamos el «Valor mínimo de coincidencia» a 75 y seleccionamos «Aplicar traducción automática»:
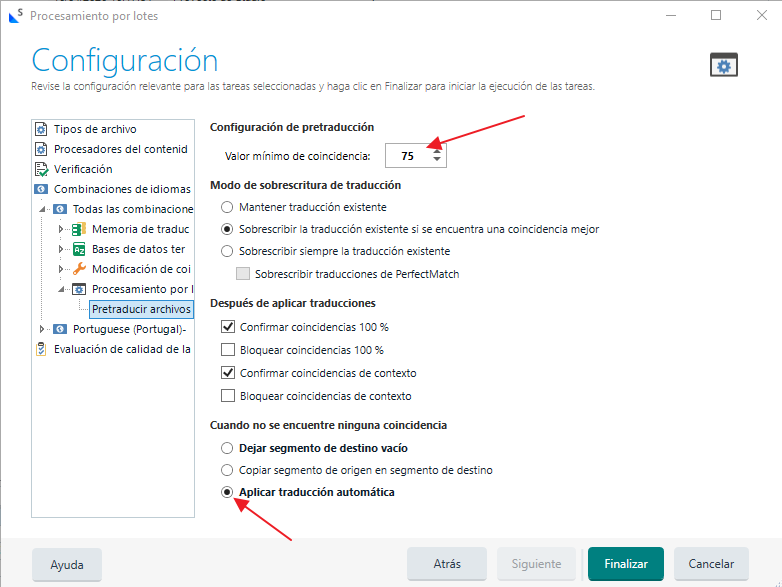
Vemos que en los segmentos que quedaban vacíos se ha aplicado la traducción automática:
Ya estaría listo el sdlxliff para ser poseditado así que lo guardaríamos junto con el análisis de Trados como habitualmente en Plunet.
4. Posedición y verificación
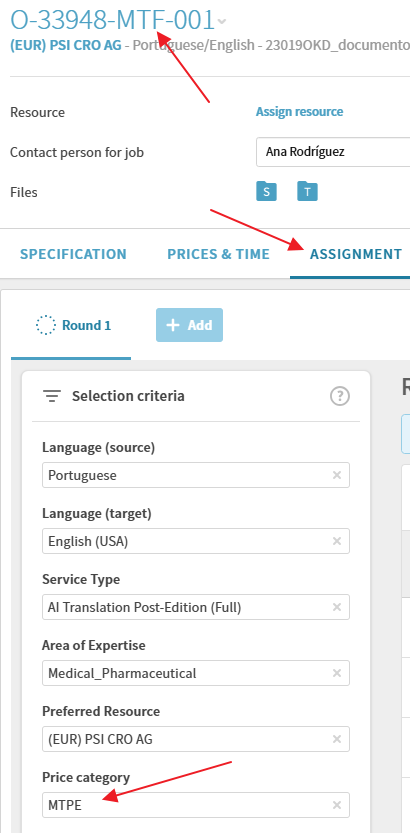
Preparamos el job en Plunet seleccionando la opción AI Translation Post-Edition (Full) (MTF) o el workflow correspondiente a lo que necesitemos.
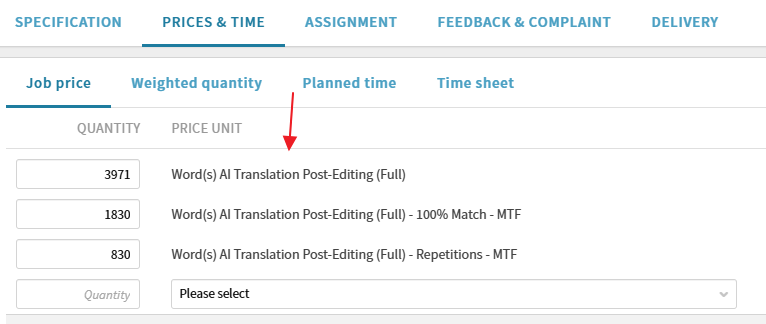
En ASSIGNMENT la Price category será la de MTPE para que al traductor se le aplique su listado de tarifas de MTPE y en PRICES % TIME al aplicar el análisis de Trados las líneas que salgan seráN de Post-Editing.
Y ya seguimos el proceso habitual de trabajo.
Si el poseditor no está validado como MTPE y no es traductor habitual o no tiene nuestra confianza, cuando nos entregue el trabajo, haremos otro job de revisión para que un revisor realice una revisión por muestreo. Ver como proceder aquí.
Seguir con la Verificación del trabajo y control de calidad.
El sdlxliff una vez comprobado se guardará en SP>PM>TMs>aa-ToUpdate>MTPE>Medical>PSI.
5. Trabajos de MTPE en archivos con filenames
Por el tipo de traducción que el cliente nos pide, los filenames no pueden traducirse mediante MTPE y requieren traducción exclusivamente humana por lo que se podrá realizar MTPE en la parte del documento que no tiene filenames y humana en la parte del documento que los contiene.
Presupuesto
Pasamos el archivo por Abbyy como normalmente y generamos el word en sucio. Buscamos los filenames y los eliminamos.*
Analizamos el word sin los filenames en Trados con la TM sin el motor de TA e incluimos el report en Plunet.
Aparte, contabilizamos los filenames que tiene el pdf sumándolos a ojo. Después multiplicamos el número de filenames por 10 y el resultado será el que añadamos en el presupuesto.
Creamos el presupuesto en Plunet seleccionando Machine Translation en Project Category, la ISO9001:2015 & ISO18587:2020 en Quality (ISO) y DL en MT engine tal y como está explicado en la parte GENERAL del curso y aplicando el listado de tarifas de MTPE al análisis de Trados. Luego cambiamos el listado de tarifas al estándar T+R y añadimos una línea de Word(s) Translation (New) – TRA donde añadiremos el volumen de palabras de los filenames.
Añadiremos además:
- el cargo de Word(s) File Preparation (recordemos que es un pdf) de todas las palabras incluidas las de lo filenames multiplicados por 10
- la suma del cargo de Hour(s) File Preparation porque para PSI cualquier trabajo de MTPE requiere un cargo de preparación de archivos de 7 minutos por documento redondeando en cuartos de hora y con un mínimo de 0,5 h más el cargo de preparación de archivos adicional por esta manipulación especial de separar los filenames de 7 minutos por documento redondeando en cuartos de hora y con un mínimo de 0,5 h.
*Forma alternativa de contar los filenames: una vez que tengamos todas las páginas leídas correctamente, generamos el nuevo Word, y vamos a la parte donde comienzan los filenames. Nos paramos sobre la columna de los filenames y nos va a aparecer una flechita negra, hacemos click y se selecciona toda la columna.
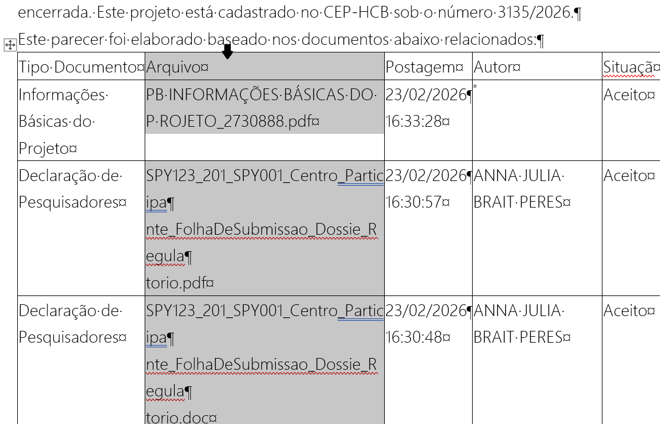
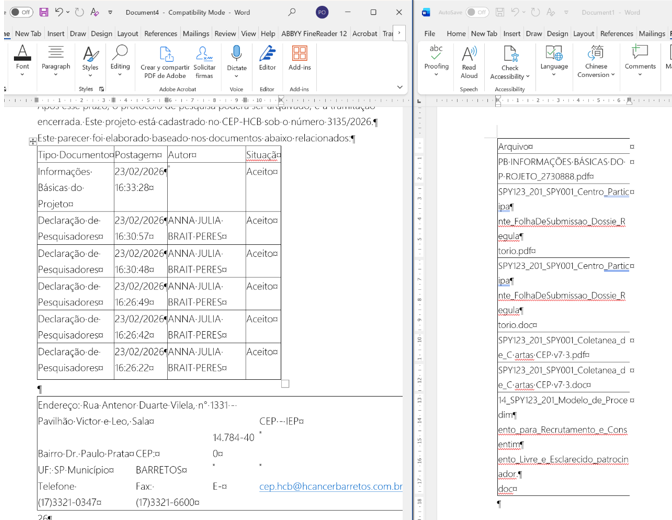
Una vez que la tenemos seleccionada, la cortamos y pegamos en un nuevo Word (ctrl + X con la columna seleccionada y ctrl+V en el nuevo Word). Esto lo tendremos que repetir varias veces porque las columnas salen separadas en el Word sucio, por lo que es recomendable abrir los dos Words desde los que vamos a copiar/pegar, uno al lado del otro, para trabajar más fácil.
Una vez que tengamos todas las columnas de filenames pegadas una debajo de la otra, nos quedará un archivo únicamente con los filenames, y el otro con todo el resto del contenido y SIN los filenames.
Para obtener el recuento de los filenames, vamos a Buscar y reemplazar (ctrl+L, o ctrl+H si tenemos Word en inglés) y reemplazamos todas las instancias de enter (^p) por nada (lo dejamos vacío).
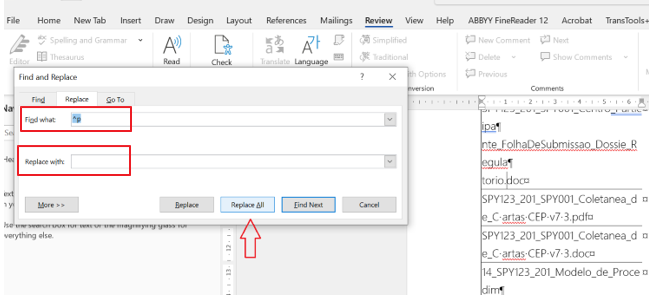
Una vez que tengamos todos los filenames, uno debajo del otro y sin los enters, simplemente miramos la cantidad de párrafos y ya tenemos la cantidad de filenames.
Creación del proyecto
Una vez que tengamos la confirmación del cliente y el word limpio, procederemos a crear el proyecto en Trados según lo explicado en la parte GENERAL del curso.
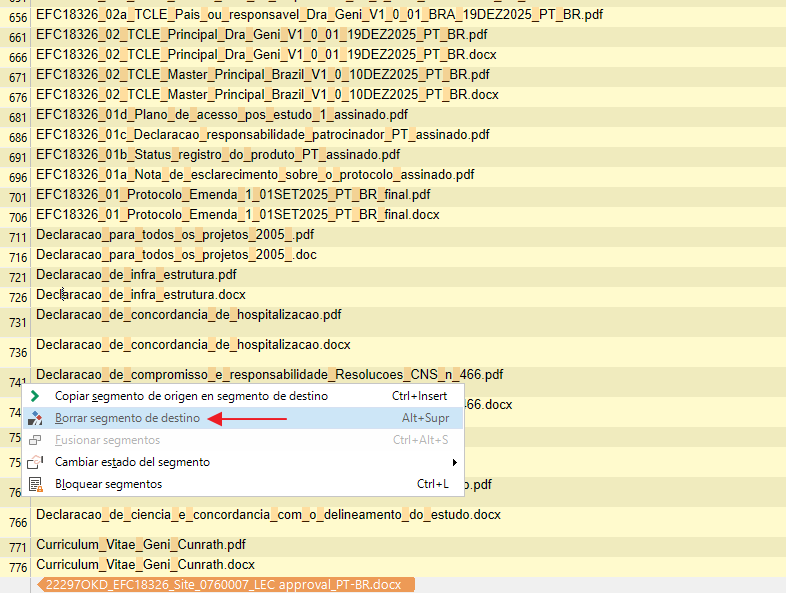
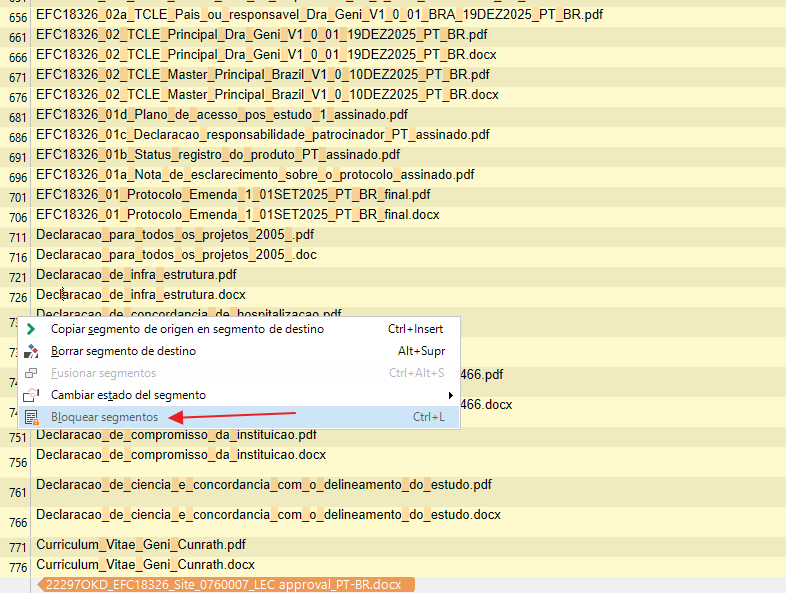
Cuando tengamos el sdlxliff pretraducido con la TM y el motor de TA, buscaremos los filenames poniendo en Buscar de la pestaña de Revisión un guión bajo para que así sólo podamos ver los segmentos con filenames, echaremos un vistazo para ver que están bien y con los segmentos seleccionados, haremos click con el botón derecho y marcaremos Borrar segmento de destino y Bloquear segmentos:

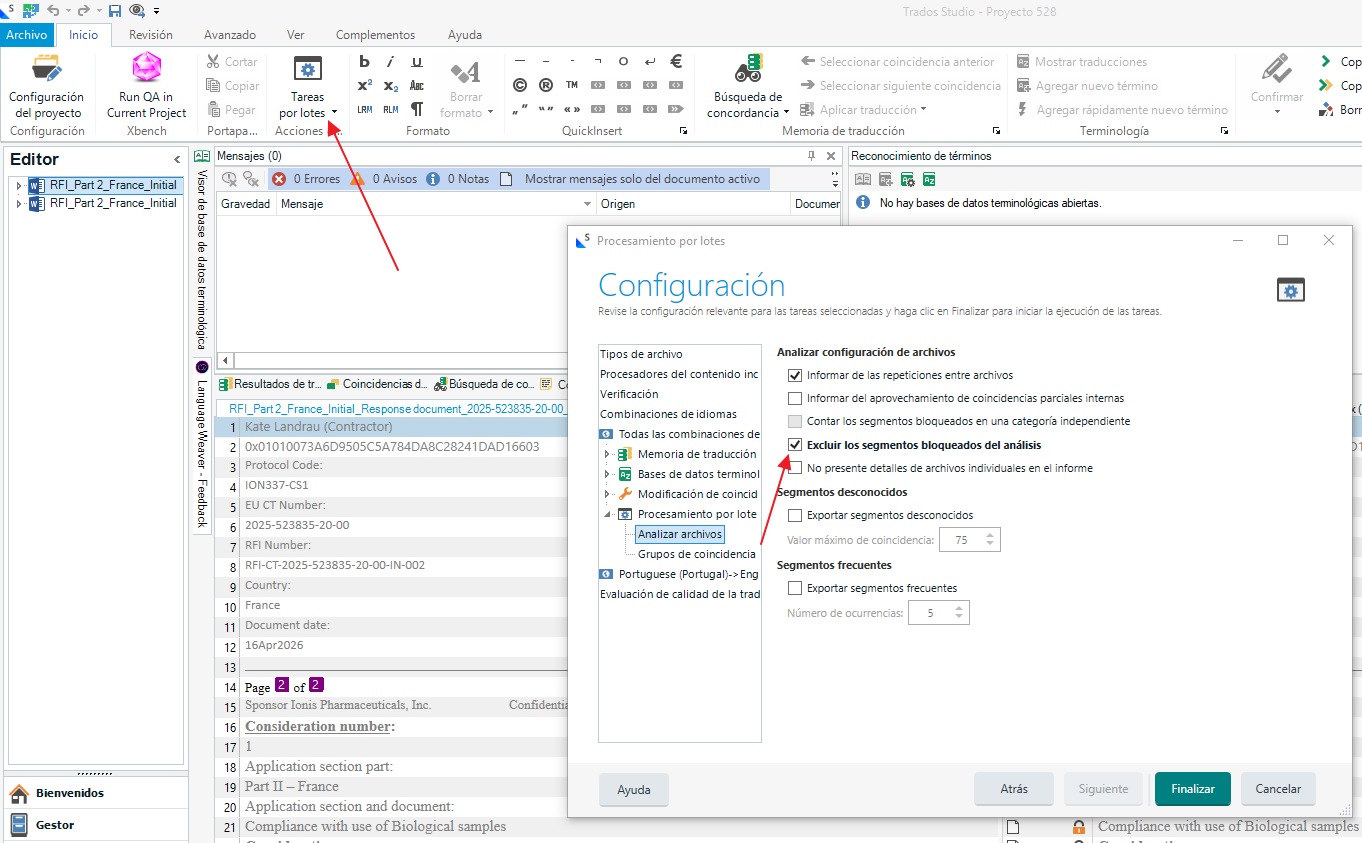
Iremos a Tareas por lotes y analizaremos de nuevo el documento seleccionando la opción de Excluir los segmentos bloqueados del análisis:
Desbloquearemos los segmentos bloqueados y guardaremos el sdlxliff y el nuevo análisis en Plunet.
Así, el traductor ya podrá poseditar los segmentos pretraducidos con la TM y con el motor de traducción y traducir desde cero los segmentos con filenames.
Posedición y traducción de filenames
Crearemos el job de MTF y en la pestaña de ASSIGNMENT, seleccionaremos al traductor y haremos click en Review:
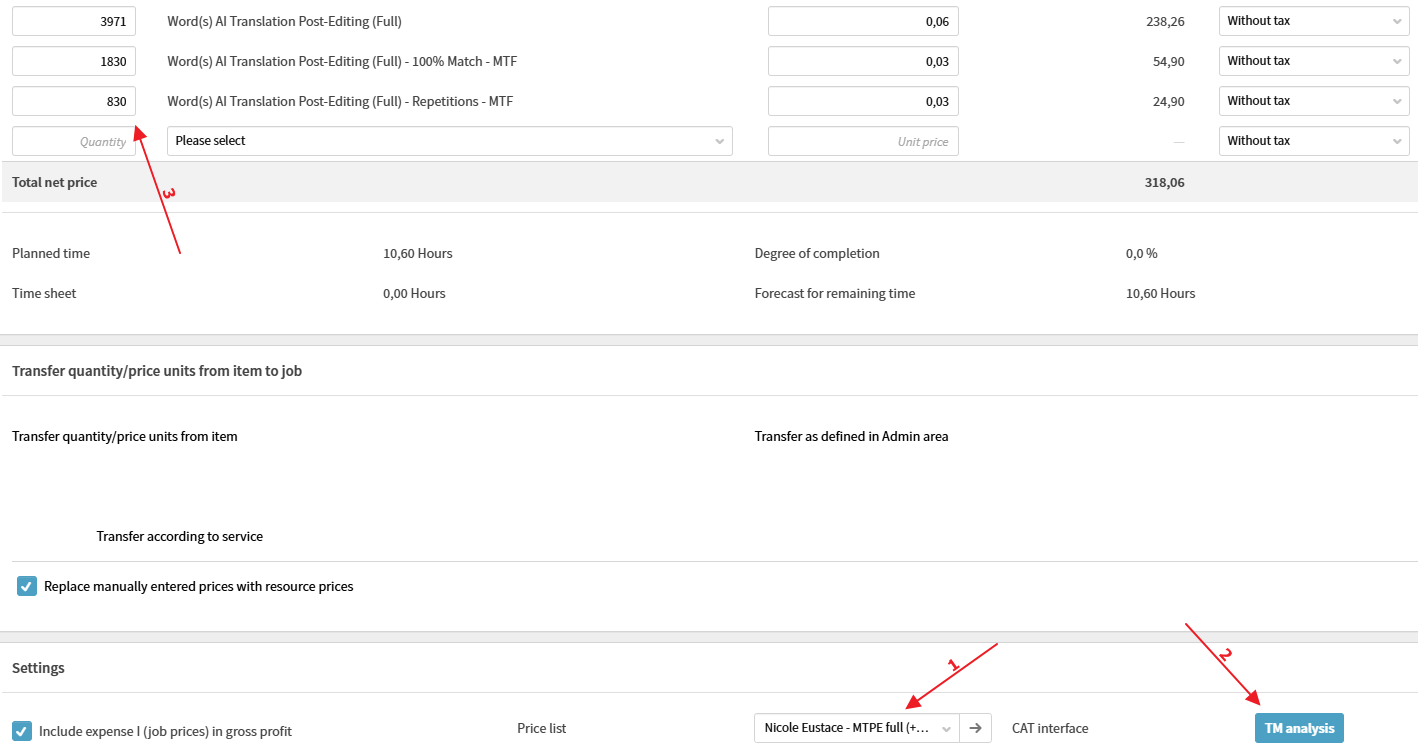
Aplicaremos el listado de tarifas de MTPE del traductor al análisis de Trados:
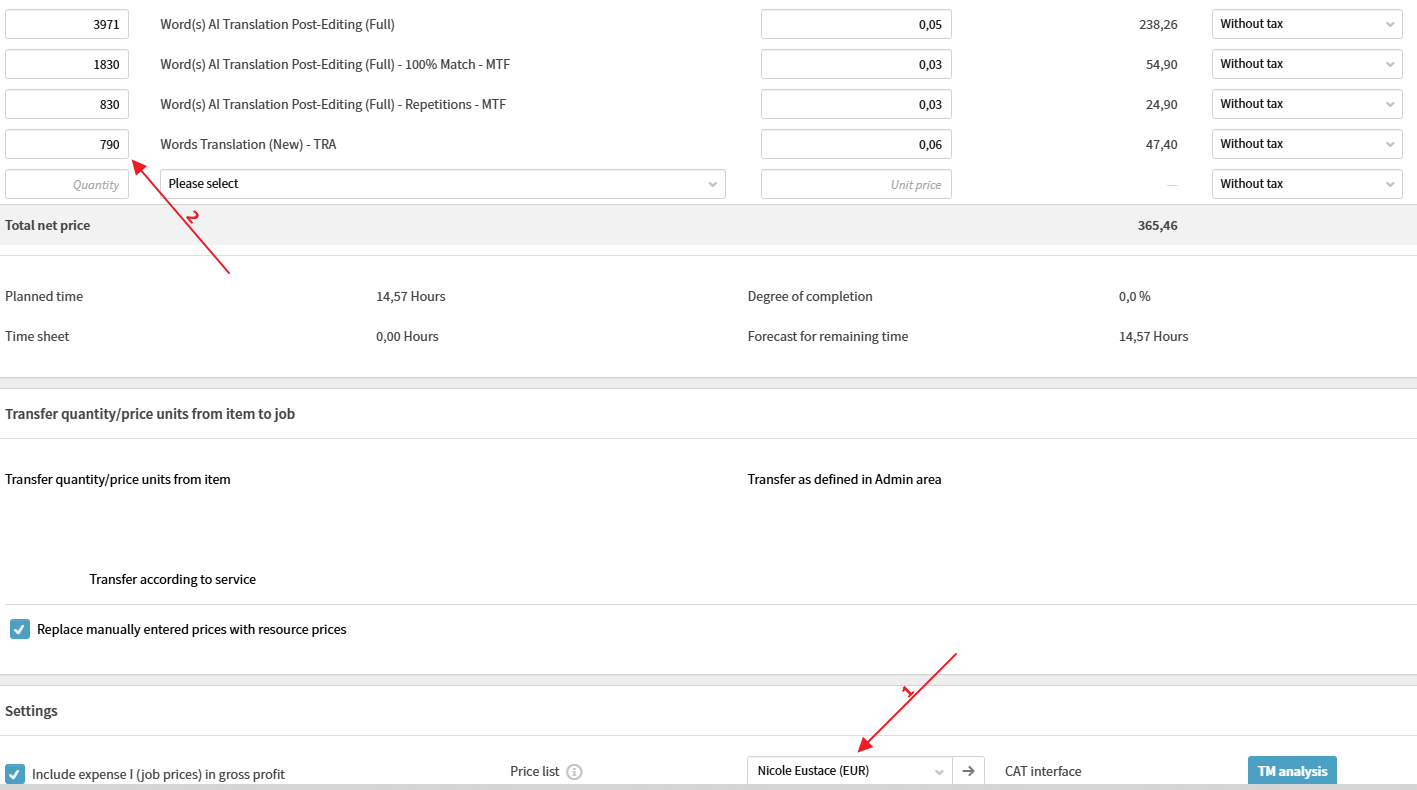
Luego, cambiaremos al listado de tarifas estándar del traductor y le añadiremos manualmente la línea de Word(s) Translation (New) – TRA con el recuento de los filenames x 10 (al igual que hemos hecho con el cliente):
En Comentarios le diremos al traductor algo similar a esto:
Please note the filenames included in the files need to be translated with human translation, as the engine does not work due to the structure the filenames have. You will identify them as the segments that are empty (no output from the TM or MT). Please make sure you use the format described in the style guide when translating them.
Y se lo mandaremos.
Como los filenames se deben revisar, cuando el traductor nos envíe el sdlxliff, bloquearemos todos los segmentos excepto los se los filenames y se lo pasaremos al revisor.
Si el traductor no está validado, además de los segmentos con filenames tendremos que desbloquear los segmentos necesarios para realizar una revisión por muestreo.
Seguir con la Verificación del trabajo y control de calidad.
Una vez verificado todo, crearemos dos sdlxliff:
- uno con la traducción rechazada de los segmentos con los filenames: guardaremos el sdlxliff en SP>PM>TMs>aa-ToUpdate>MTPE>Medical>PSI
- otro con la traducción rechazada de los segmentos sin filenames: guardaremos el sdlxliff en SP>PM>TMs>aa-ToUpdate>Medical>PSI
* Forma alternativa de filtrar los segmentos con filenames en Trados: previamente, en el word en limpio, habremos resaltado en amarillo la columna de filenames. Asegurarse de que la primera fila que dice “Arquivo” quede sin resaltar:

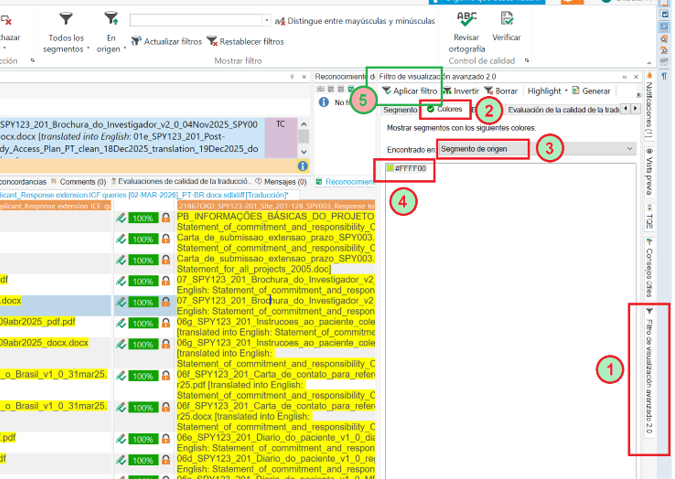
En Plunet, vamos al advanced display filter y marcamos que nos filtre los segmentos resaltados.