

Particularidades idiomas
1. Particularidades de algunos idiomas
Puesto que algunos idiomas pueden representar dudas a la hora de tratarlos en las diferentes herramientas o proceso de trabajo, este artículo pretende disipar dichas dudas ante algunos idiomas. En caso de que algún otro idioma pueda representar dudas y no esté indicado en este listado, por favor indicadlo mediante la sección de Comentarios inferior.
En este sentido, en el siguiente listado de idiomas se informa de:
- la variante considerada “estándar” por Okodia.
- los códigos a utilizar a la hora de renombrar los sdlxliff para subirlos a la carpeta ToUpdate.
- las variantes de idiomas a utilizar al crear los proyectos en Trados y en Plunet.
- las particularidades a tener en cuenta en algunos idiomas.
Alemán
Variante estándar: German (Germany), o simplemente German.
- Códigos
- DE = German (Germany), o simplemente German
- DE_AT = German (Austria)
- DE_CH = German (Switzerland)
- Sdlxliff
- Source: DE
- Target: código de la variante real
- Trados
- Source: German (Germany)
- Target: German (Germany), o variante real, en función de las características del trabajo.
- Plunet
- Source: German
- Target: German, o variante real, en función de las características del trabajo.
- Observaciones: Si el cliente nos dice que necesita una traducción al alemán para ser utilizada en Austria o en Suiza, habría que reconfirmar con él que realmente lo quiere a alemán de Austria o a alemán de Suiza porque a veces aunque digan que quieren usar el documento en esos países, necesitan la traducción al alemán estándar, es decir al de Alemania. En caso de que el cliente reconfirme que lo quiere en alemán de Austria o alemán de Suiza es necesario reconfirmar la tarifa con la persona responsable del equipo o Dirección.
Árabe
Variante estándar: Arabic (MSA), o simplemente Arabic.
- Códigos
- AR = Arabic (MSA), o simplemente Arabic
- Sdlxliff
- Source: AR
- Target: AR
- Trados
- Source: Arabic (Saudi Arabia)
- Target: Arabic (Saudi Arabia)
Nota: Puesto que el árabe no tiene versión genérica en Trados, en Okodia hemos convenido que la versión “estándar” para Trados es el árabe de Arabia Saudi, y así es como están configuradas nuestras TM. En caso de que el idioma Target tuviera que ser específico de algún país, por requerimientos del cliente, deberíamos indicar la variante real en Target.
- Plunet
- Source: Arabic
- Target: Arabic
- Observaciones: El árabe siempre se suele escribir como árabe estándar (MSA, Modern Standard Arabic). Si el cliente necesita una variante específica lo indicará directamente, aunque si lo indica sí se le debe explicar que el árabe estándar es como normalmente se escribe, ya que las variantes marroquí, libanesa, etc. Solamente se usan en el oral, pero no como forma escrita (aunque puede hacerse a petición del cliente, siempre previa consulta de que podemos hacerlo con algún proveedor).
Chino
Variante estándar: Simplified Chinese (Mandarin), o simplemente Chinese.
- Códigos
- ZH = Simplified Chinese (Mandarin), o simplemente Chinese
- ZH_TW = Traditional Chinese (Mandarin, hablado en Taiwan)
- ZH_HK = Traditional Chinese (Mandarin, hablado en Hong Kong)
Nota: Cuando se habla de “chino”, se refiere al chino mandarín. No confundir, por lo tanto, con cantonés o taiwanés, ya que son idiomas diferentes del chino, aunque coincida su alfabeto (escritura).
- Sdlxliff
- Source: ZH / ZH_TW / ZH_HK
- Target: ZH / ZH_TW / ZH_HK
- Trados
- Source: Chinese (Simplified China) / Chinese (Traditional Taiwan) / Chinese (Traditional Hong Kong)
- Target: Chinese (Simplified China) / Chinese (Traditional Taiwan) / Chinese (Traditional Hong Kong)
- Plunet
- Source: Chinese (Simplified) o Chinese (Traditional)
- Target: Chinese (Simplified) o Chinese (Traditional)
- Observaciones:
En cuanto a la lengua oral, existen principalmente (entiéndase principalmente como los idiomas que más habitualmente solicitan los clientes) los siguientes:
-
- chino mandarín: También llamado simplemente chino, pero también chino estándar, chino continental, dialecto de Pekín, Putonghua. Este idioma se puede escribir con el alfabeto simplificado o con el alfabeto tradicional, en función del país o región en el que se pretenda utilizar.
- Escritura con chino simplificado: China continental (excepto región de Cantón) y Singapur
- Escritura con chino tradicional: Taiwan y Hong Kong
- chino cantonés, o simplemente cantonés: Este idioma se suele escribir con alfabeto tradicional.
- Escritura con chino tradicional: Cantón y Hong Kong
- taiwanés: Este idioma se suele escribir con alfabeto tradicional.
- Escritura con chino tradicional: Taiwan
- chino mandarín: También llamado simplemente chino, pero también chino estándar, chino continental, dialecto de Pekín, Putonghua. Este idioma se puede escribir con el alfabeto simplificado o con el alfabeto tradicional, en función del país o región en el que se pretenda utilizar.
La mayoría de dudas/problemas suelen surgir cuando tenemos en mente Taiwan o Hong Kong, pues en esos lugares se utilizan 2 idiomas diferentes, aunque la escritura siempre es la tradicional. En este sentido, se indica también la siguiente tabla por territorios:
-
- China continental (excepto Cantón): chino mandarín – escritura simplificada
- Singapur: chino mandarín – escritura simplificada
- Cantón:chino cantonés – escritura tradicional
- Taiwan:chino mandarín – escritura tradicional
- Taiwan: taiwanés (idioma no relacionado con el chino)– escritura tradicional
- Hong Kong: chino mandarín – escritura tradicional
- Hong Kong: chino cantonés – escritura tradicional
Más información en: https://www.argosmultilingual.com/blog/when-character-counts-simplified-chinese-vs-traditional-chinese
Español
Variante estándar: Spanish (Spain), o simplemente Spanish.
- Códigos
- ES = Spanish (Spain), o simplemente Spanish
- ES_AR = Spanish (Argentina)
- ES_Latam = Spanish (Latin America)ES_US = Spanish (USA)
- ES_MX = Spanish (Mexico)
- ES_CU = Spanish (Cuba)
- ES_CO = Spanish (Colombia)
- ES_CH = Spanish (Chile)
- ES_PE = Spanish (Peru)
- Sdlxliff
- Source: ES
- Target: código de la variante real
- Trados
- Source: Spanish (Spain)
- Target: Spanish (Spain), o variante real, en función de las características del trabajo.
- Plunet
- Source: Spanish
- Target: Spanish, o variante real, en función de las características del trabajo.
- Observaciones:
Francés
Variante estándar: French (France), o simplemente French.
- Códigos
- FR = French (France), o simplemente French
- FR_CA = French (Canada)
- Sdlxliff
- Source: FR
- Target: código de la variante real
- Trados
- Source: French (France)
- Target: French (France), o variante real, en función de las características del trabajo.
- Plunet
- Source: French
- Target: French, o variante real, en función de las características del trabajo.
- Observaciones: Si el cliente nos dice que necesita una traducción al francés para ser utilizada en Bélgica o Suiza, habría que reconfirmar con él que realmente lo quiere a francés de Bélgica o a francés de Suiza porque a veces aunque digan que quieren usar el documento en esos países, necesitan la traducción al francés estándar, es decir al de Francia. En caso de que el cliente reconfirme que lo quiere en francés de Bélgica o francés de Suiza es necesario reconfirmar la tarifa con la persona responsable del equipo o Dirección. En cambio, en caso de solicitarlo a francés de Canadá, se podrá hacer directamente puesto que ya sabemos por experiencia que algunos clientes lo requieren con esta variedad específica.
Inglés
Variante estándar: English (neutro), o simplemente English. A efectos de Plunet/Trados, la variante estándar es English (USA).
- Códigos
- EN = English (neutro, genérico), o English (USA) en Trados
- EN_UK = English (UK)
- Sdlxliff
- Source: EN
- Target: EN / EN_UK
- Trados
- Source: English (United States)
- Target: English (United States), o variante real, en función de las características del trabajo.
Nota: El idioma source siempre será English (United States), aunque sepamos que la traducción se hace desde una variante específica de inglés. En target, la variante estándar siempre será English (United States), a menos que para algún trabajo en concreto se deba hacer a English (United Kingdom) porque hay una TM específica codificada de esa forma).
- Plunet
- Source: English (USA) / English (UK)
- Target: English (USA), o variante real, en función de las características del trabajo.
Nota: El idioma source siempre será English (United States), a menos que el cliente/trabajo sea específicamente de Reino Unido. En target, la variante estándar siempre será English (United States), a menos que el cliente indique expresamente su preferencia hacia otra variante de inglés.
- Observaciones: Cuando se trata de idioma “estándar” y el cliente pide la traducción simplemente a “inglés”, consideraremos que realizaremos la traducción al inglés que más nos convenga en función de los recursos disponibles, tratando que la traducción sea lo más neutra posible. En caso de que el cliente indique su preferencia hacia una de las diferentes variantes, la traducción sí deberá realizarse a esa variante, independientemente de cómo deba indicarse en Trados/Plunet.
Malayo
Variante estándar: Malay (Malaysia), o simplemente Malay.
- Códigos
- MS = Malay (Malaysia), o simplemente Malay
- MS_SG = Malay (Singapore)
- Sdlxliff
- Source: MS
- Target: MS / MS_SG
- Trados
- Source: Malay (Malaysia)
- Target: Malay (Malaysia), o variante real, en función de las características del trabajo.
- Plunet
- Source: Malay
- Target: Malay, o variante real, en función de las características del trabajo.
- Observaciones:
Neerlandés / Flamenco
Variante estándar: Dutch (Netherlands), o simplemente Dutch.
- Códigos
- NL = Dutch (Netherlands), o simplemente Dutch.
- NL_NL = Dutch (Netherlands), o simplemente Dutch.
- NL_BE = Dutch (Belgium), o Flemish.
- Sdlxliff
- Source: NL
- Target: NL_NL / NL_BE
Nota: Como idioma source siempre consideraremos el idioma como uno solo. Como idioma target sí diferenciaremos entre variantes.
- Trados
- Source: Dutch (Netherland)
- Target: Dutch (Netherlands), o variante real, en función de las características del trabajo.
- Plunet
- Source: Dutch
- Target: Dutch, o variante real, en función de las características del trabajo.
- Observaciones: Como idioma source, siempre consideraremos el idioma como uno solo, y será “Dutch”, independientemente de si se nos indica que es Neerlandés/Holandés/Flamenco. Como idioma target, consideraremos que hablamos de Dutch (Netherlands), es decir, neerlandés/holandés, a menos que el cliente nos indique expresamente que lo quiere para neerlandés/holandés de Bélgica o Flamenco, en cuyo caso lo deberemos traducir a esa variante e indicar en target de ese modo donde corresponda.
Portugués
Variante estándar: Portuguese (Portugal), o simplemente Portuguese.
- Códigos
- PT = Portuguese (Portugal), o simplemente Portuguese.
- PT_BR = Portuguese (Brazil)
- Sdlxliff
- Source: PT
- Target: PT / PT_BR
- Trados
- Source: Portuguese (Portugal)
- Target: Portuguese (Portugal), o variante real, en función de las características del trabajo.
- Plunet
- Source: Portuguese
- Target: Portuguese, o variante real, en función de las características del trabajo.
- Observaciones: Cuando el cliente nos indique que quiere traducir a portugués, siempre consideraremos que se trata de la versión que consideramos estándar, es decir portugués de Portugal, a menos que el cliente nos indique portugués de Brasil. En cualquier caso, conviene aclarar con el cliente la variedad target antes de comenzar, y especialmente si el cliente es latinoamericano o si se tiene la sospecha de que los documentos irán a Brasil (por ejemplo si en la traducción se habla de algo brasileño).
Serbio
Variante estándar: Serbian (Cyrillic) y Serbian (Latin).
- Códigos
- SR_lat = Serbian (Latin)
- SR_cyr = Serbian (Cyrillic)
- Sdlxliff
- Source: SR_lat / SR_cyr
- Target: SR_lat / SR_cyr
- Trados
- Source: variante real, en función de las características del trabajo.
- Target: variante real, en función de las características del trabajo.
- Plunet
- Source: variante real, en función de las características del trabajo.
- Target: variante real, en función de las características del trabajo.
- Observaciones: El idioma serbio puede escribirse indistintamente con alfabeto latino o cirílico. Cuando se trata de idioma source, es fácil ver con qué alfabeto está escrito. En cambio, cuando se trata de idioma target es necesario que el cliente indique el alfabeto con el que quiere que se traduzca.
Tailandés
Variante estándar: Thai (Thailand), o simplemente Thai.
- Códigos
- TH = Thai
- Sdlxliff
- Source: TH
- Target: TH
- Trados
- Source: Thai (Thailand)
- Target: Thai (Thailand)
- Plunet
- Source: Thai
- Target: Thai
- Observaciones: Antes de trabajar con Thai es absolutamente imprescindible instalar el paquete de idioma.
Cuando Thai es source, ni Word ni Trados calculan correctamente las palabras en tailandés, por lo que en este idioma tendremos en cuenta los caracteres. Pero, con el dato de caracteres, calcularemos el equivalente en palabras.
Hemos establecido un cálculo para el cliente de 4 caracteres por palabra, es decir, para calcular los recuentos de palabras en base a los caracteres que nos dé Trados, dividiremos el volumen de caracteres entre 4. Tendremos que incluir en Plunet el recuento de cada rango manualmente (en el caso de PSI se ha creado una pricelist específica que hace el cálculo de forma automática, por lo que si fuese necesario para otros clientes también se podría hacer. En tal caso, comentar con Luis). Importante: No aplicaremos fuzzies, de ningún tipo, tampoco los del 100%, simplemente aplicaremos repeticiones. Excepto las repeticiones, que se considerarán a la mitad, el resto serán todo palabras nuevas).
| Cálculo Estándar |
|
| Thai (source) |
|
Ejemplo: analizamos los editables en un proyecto creado con la combinación de idiomas correspondiente y la TM del cliente. Trados nos da el siguiente recuento:
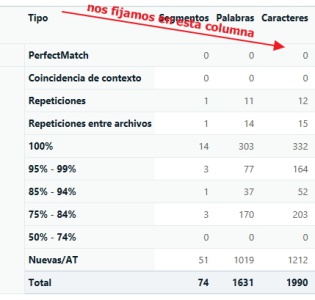
En Plunet, para el cliente pondremos:
7 palabras repetidas (15+12=27 caracteres repetidos dividido entre 4. Redondeamos al alza.)
472 palabras nuevas (1990 caracteres totales – 27 caracteres repetidos=1963 caracteres entre nuevos y resto de fuzzies dividido entre 4. Redondeamos al alza.)
Para el proveedor, el cálculo se realizará de la misma manera pero calcularemos a 5 caracteres por palabra (tampoco aplicaremos fuzzies, sólo repeticiones y palabras nuevas)
Existe una calculadora (Calculadora tailandés) disponible para facilitar los cálculos. Seleccionamos “Calcular número de palabras”, incluimos el número de caracteres y seleccionamos “Cliente”.
NOTA: la calculadora solo hace la división entre 4. Cuando se use, habrá que calcular por separado las palabras repetidas y las palabras nuevas (nuevas = new + todos los fuzzies).
Tamil
Variante estándar: Tamil (India), o simplemente Tamil.
- Códigos
- TA = Tamil
- Sdlxliff
- Source: TA
- Target: TA
- Trados
- Source: Tamil (India)
- Target: Tamil (India)
- Plunet
- Source: Tamil
- Target: Tamil
- Observaciones: Aunque el cliente solicite Tamil de Singapur, se trata del Tamil genérico, el mismo que Tamil (India) por lo que usaremos Tamil (India) en Trados.
2. Criterios de contabilización general para los idiomas más habituales
- Recuentos por palabras origen (source):
- Idiomas con alfabeto latino (español, inglés, francés…)
- Idiomas con alfabeto cirílico (ruso, ucraniano, búlgaro…)
- Idiomas con alfabeto griego (griego)
- Idiomas con alfabeto árabe (árabe, persa)
- Idiomas con alfabeto georgiano (georgiano)
- Idiomas con alfabeto tamil (tamil)
- Idiomas con alfabeto coreano (coreano)
- Idiomas con alfabetos japoneses (japonés) (ver Nota)
- Idiomas con alfabetos chinos (chino tradicional, chino simplificado) (ver Nota)
- Recuentos por caracteres origen (source) convertidos a palabras:
- Idiomas con alfabeto tailandés (tailandés): contabilizaremos los caracteres (Word/Trados) y dividiremos entre 4 para obtener un recuento de palabras aproximado, que se usará para Plunet. En caso de ser necesario, se puede crear una pricelist específica para el cliente en Plunet donde dicha conversión ya se haga de forma automática.
Nota: en chino y en japonés, hay una quasi-equivalencia carácter-palabra 1:1, lo que significa que 1 carácter equivale prácticamente a 1 palabra. En este sentido, y a efectos de simplicidad, se ha establecido un recuento por palabras igual que con la mayoría de idiomas, por lo que se contabilizarán las palabras tanto en Word como en Trados. Del mismo modo, en Plunet se seleccionará Words Translation.
No obstante, (Y SOLAMENTE COMO INFORMACIÓN) es interesante conocer esta funcionalidad de Trados (aunque por defecto la dejaremos siempre desmarcada) por si se necesitase en algún momento específico:
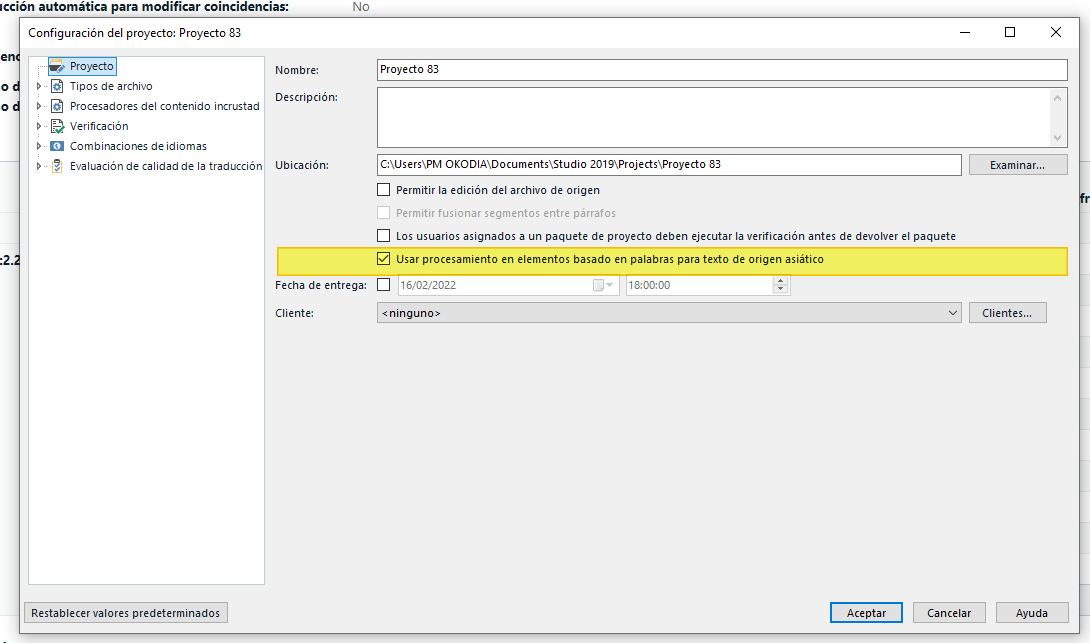
Si se deja desmarcada la casilla, Trados cuenta cada carácter asiático (chino o japonés) como una palabra, lo cual no siempre es 100% exacto ya que, por ejemplo en chino, puede haber palabras formadas por dos caracteres. En cambio, si se deja marcada, lo que hace Trados es intentar identificar los elementos que se corresponderían a una palabra, ya los formen uno o varios caracteres. Si se activa, el recuento que se obtiene es más pequeño.
En nuestro caso, sin embargo, esta opción no es relevante porque a nuestros clientes le cobramos por palabras según se obtenga de Word/Trados, y por lo tanto, sin marcar esa opción, Trados cuenta los caracteres (como palabras) y lo que sean palabras en alfabeto latino (si lo hubiera mezclado) como palabras.
Otros artículos relacionados con los idiomas:
Longitudes medias de palabras/caracteres en los diferentes idiomas