

Resource 03 – Gestión de trabajos de posedición con Trados Studio
Análisis previo
Consultar PM003 – Procedimiento general Traducción Automática y Posedición (MTPE), punto 2.1. para analizar si un texto es susceptible de usar TA.
Una vez hemos analizado que el texto cumple los requisitos para trabajar con traducción automática, podemos hacer dos cosas:
- Creamos el proyecto de Trados Studio para pasárselo al poseditor (vamos directamente al punto 2 de este artículo).
- Queremos asegurarnos de que nuestros motores de traducción automática funcionan bien con el tipo de texto, o queremos pedir disponibilidad previa a algunos recursos, o simplemente queremos decidir qué motor usar (sacaremos una muestra significativa del texto de unas 200-300 palabras y haremos una prueba con nuestros motores de traducción automática).
Características de los motores de traducción automática
A día de hoy, en Okodia contamos con dos motores de traducción privados para trabajar los textos:
- DeepL
- Tiene muchos pares de idiomas disponibles (pero limitados)
- Funciona bien con cualquier tipo de texto
- En algunos pares de idiomas, al seleccionar DeepL, podemos optar porque los resultados que vuelque el motor sean más o menos formales
- Lenguaje natural, incluso para textos de marketing
- No es un motor que se vaya actualizando con nuestros trabajos
- ModernMT
- Todos los pares de idiomas disponibles
- Funciona especialmente bien con textos de tipo legal
- Aprende de nuestras memorias de traducción o glosarios antes de pretraducir un texto, si así lo elegimos:
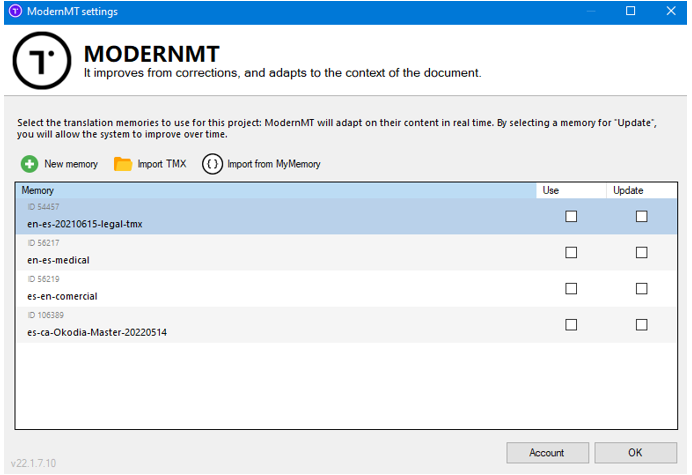
- ChatGPT
- Tiene muchos pares de idiomas disponibles
- Funciona bien con cualquier tipo de texto
- Dispone de plugin para Trados Studio, instalado ya por defecto en Trados. También disponemos de un desarrollo interno incluido en nuestro CRM
- Lenguaje natural, incluso para textos de marketing
- No es un motor que se vaya actualizando con nuestros trabajos
- El plugin de Trados permite configuración en cuanto a posibles prompts ya predefinidos para usar, además de poder añadir un prompt personalizado.
Cómo hacer pruebas previas con los motores de traducción automática
Si lo que queremos es saber qué motor de traducción automática usar, usaremos la herramienta “MT Comparison”, disponible en la Página de Descargas de la Okopedia, en «Plugins Trados Studio 2022«.
Esta herramienta nos permite comparar los resultados de diferentes motores de traducción automática que tengamos activos en nuestro proyecto.
Paso a paso:
- Extraemos una muestra representativa de unas 200-300 palabras del texto (es innecesario hacerlo de más volumen, porque el poseditor no mirará más volumen e incluso se podría sentir abrumado, y por otro lado supone un coste adicional para la empresa puesto que los motores de traducción automática cobran según las palabras que les pedimos pretraducir)
- Creamos un nuevo proyecto en Trados Studio, de manera convencional y sin añadir ninguna memoria de traducción.
- Una vez lo tengamos creado, iremos a “Configuración del proyecto” y en “Combinaciones de idiomas” añadiremos los motores de traducción automática que queramos comparar y clicamos en “Aceptar” (para ello es necesario haber instalado anteriormente los plugins de los motores de traducción automática para Trados DeepL y ModernMT, disponibles en la Página de Descargas de la Okopedia, en «Plugins Trados Studio 2022«):
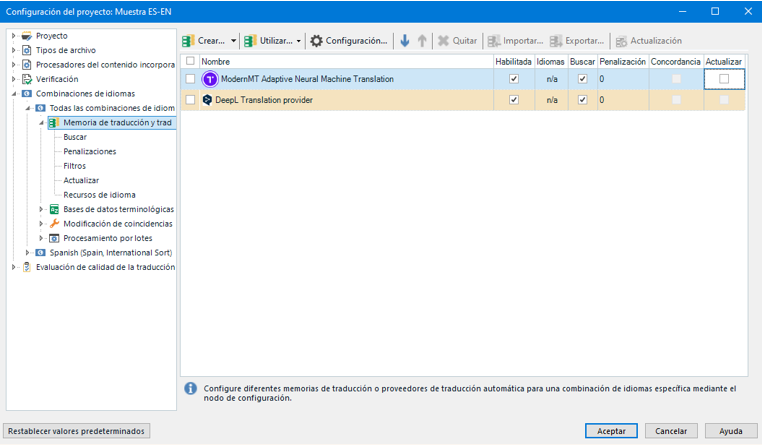
NOTA IMPORTANTE: Para sacar muestras o comparaciones con los motores es importante NO tener clicada la opción de “Actualizar” (solo disponible para ModernMT).
- Colocándonos en la vista de “Proyectos” de Trados Studio, clicaremos con el botón derecho en el proyecto en cuestión y, al final de la lista, seleccionaremos “Compare MT”. Se nos abrirá la siguiente pestaña:
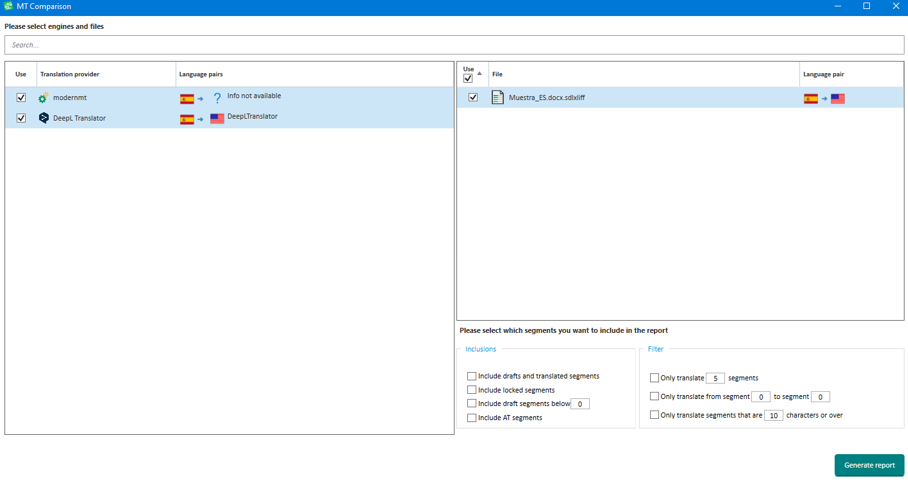
Es importante saber que esta herramienta permite seleccionar solamente un archivo para comparar, en caso de tener un trabajo con varios archivos de trabajo, o solamente sacar una muestra de uno de los motores en base a sus características (ver punto 1.1). La herramienta también nos permitirá elegir el rango de segmentos que queremos comparar:
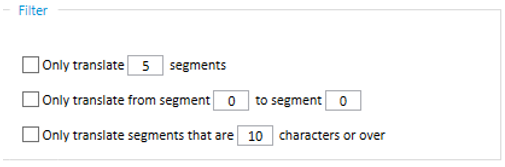
En este caso, puesto que el texto que tenemos solo tiene 225 palabras, lo compararemos entero y no seleccionaremos ningún tipo de filtro.
Cuando lo tengamos todo configurado, clicamos en “Generate Report”.
- El programa nos genera un archivo Excel con el texto origen y los resultados de los motores que hayamos elegido comparar:
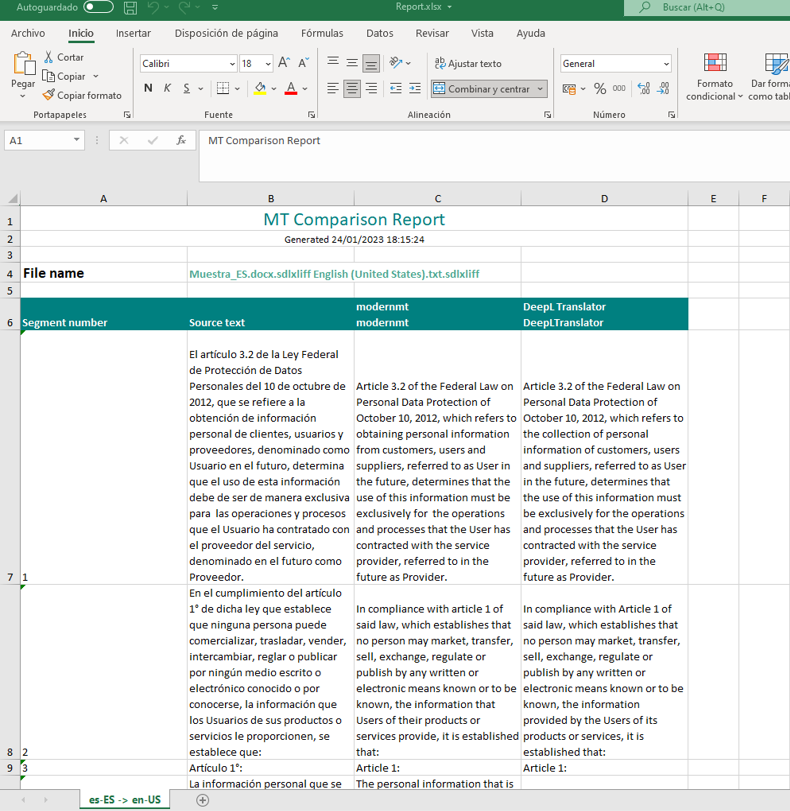
IMPORTANTE: si enviamos estas muestras comparativas a los recursos para disponibilidad, quitaremos SIEMPRE la información acerca de los motores de traducción, en este caso, presente en las columnas C y D. Podemos sustituir la información simplemente por las siglas correspondientes a cada motor.
Preparación alternativa y traducción con ChatGPT
ChatGPT dispone de plugin preinstalado por defecto en Trados, por lo que se puede utilizar como se haría con cualquier otro. Además, el propio plugin permite personalizar algunos prompts específicos e incluso añadir propios, si fuera necesario.
Si por algún motivo prefiriésemos utilizar el desarrollo propio que realizamos previo a la incorporación del plugin por defecto en Trados, también podríamos hacerlo. Este desarrollo propio tiene un aplicativo disponible en nuestro CRM > Recursos > HumanAI+ > Traducción sdlxliff que nos ayuda a traducir un sdlxliff con ChatGPT.
Para utilizarlo, lo primero que debemos hacer es generar un archivo sdlxliff creado mediante Trados.
En el caso de la realización de pruebas previas, crea un sdlxliff solamente con el mismo texto de prueba que utilices para los otros dos motores de traducción automática, y sin utilizar ninguna memoria de traducción. Puesto que ese sdlxliff será «limpio», es decir, sin nada de texto de ninguna memoria de traducción, simplemente tendrás que subir el archivo y descargarlo traducido una vez se haya realizado el proceso. En este caso, en el Excel generado con los otros dos motores, deberás añadir también manualmente los segmentos obtenidos con ChatGPT, de forma que la traductora pueda valorar los 3 en paralelo.
En el caso de utilización real de ChatGPT (porque en el análisis previo haya resultado ser el mejor), crea el sdlxliff con el archivo completo (o lo que necesites) y utilizando la memoria de traducción que necesites, puesto que ya se trataría de un encargo real. Una vez obtenido dicho sdlxliff tendrás que subirlo al aplicativo e indicar las opciones que te interesen en función de tu proyecto:
- No traducir si el porcentaje es superior a: Esto significa que si para tu proyecto has utilizado una memoria de traducción y quieres que el traductor aproveche los fuzzies del X% provenientes de la memoria, deberías cambiar ese porcentaje para que ChatGPT traduzca todo excepto esos fuzzies. De ese modo el traductor trabajará con un sdlxliff parcialmente traducido con ChatGPT (palabras nuevas y fuzzies más bajos) y con coincidencias de la memoria (fuzzies más altos, a partir del porcentaje que le definas).
- ¿Con qué status quieres que aparezcan los segmentos traducidos?: Puedes elegir entre «Draft» y «Translated». Si eliges «Draft», el traductor tendrá que confirmar todos los segmentos a medida que traduzca. Si eliges «Translated», el traductor solamente tendrá que confirmar los segmentos que edite. En los otros dos motores de traducción automática se suele mostrar todo como «Translated».
- ¿Quieres que aparezca el nombre del motor utilizado? En ese caso, ¿qué nombre quieres que ponga?: Puedes elegir entre «HumanAI+», «Engine3» o que no aparezca nada («Sin nombre»). El traductor nunca sabrá que se realiza con ChatGPT, pero puedes elegir el nombre que prefieras que se le muestre. A nivel interno es algo poco relevante.
Tanto el status como el nombre del motor es lo que Trados muestra aquí:
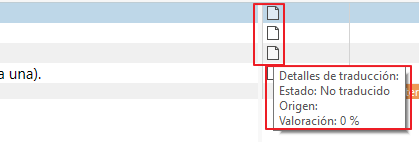
Una vez seleccionadas esas opciones y subido el archivo, en función del tamaño del mismo puede tardar más o menos tiempo en procesarse. Puedes abandonar la página y volver más tarde a descargarlo cuando aparezca finalizado aquí:
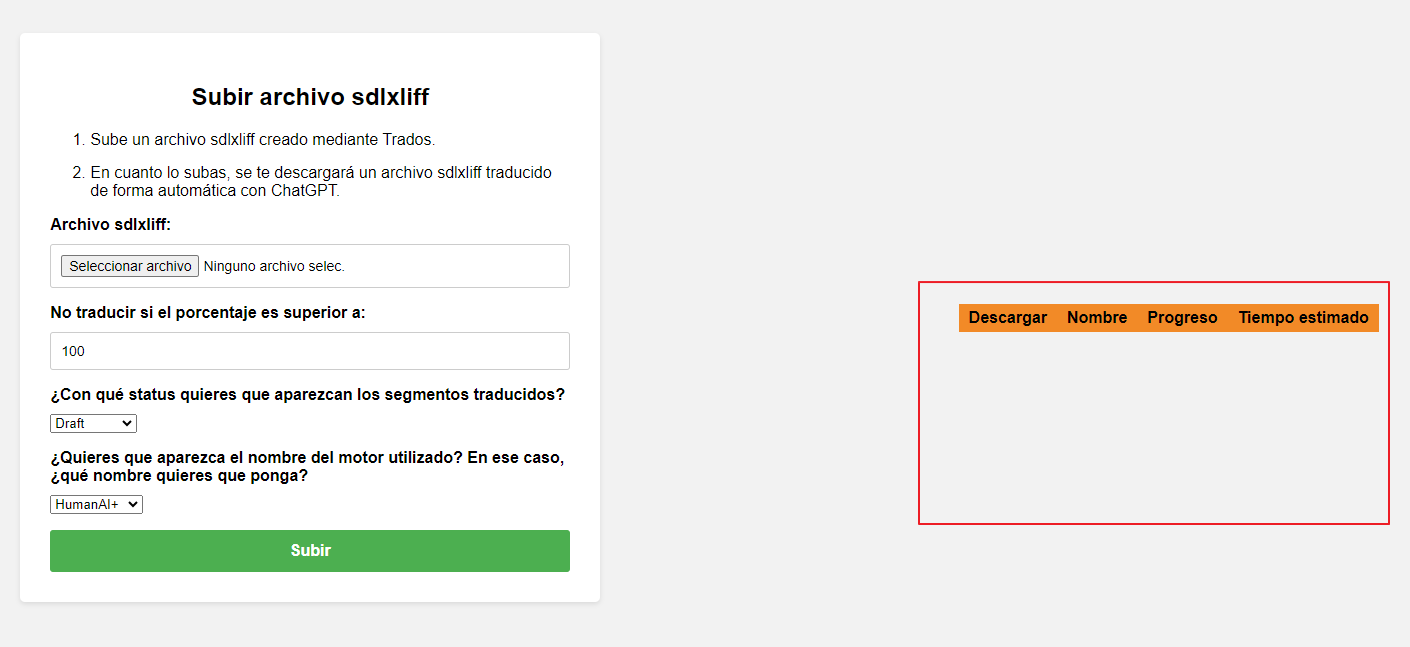
Ese sdlxliff que descargues ya será el que podrás enviar a poseditar.
Creación de proyectos y pretraducción con los motores de TA
NOTA PREVIA IMPORTANTE: A la hora de gestionar un trabajo de posedición debemos tener en cuenta qué motores o memorias de traducción añadiremos al proyecto, puesto que en función de eso los pasos a seguir serán ligeramente diferentes. Se explican a continuación cada una de las situaciones posibles:
Solamente motor de traducción automática
No nos detendremos mucho en la explicación aquí, puesto que el proceso de creación de un proyecto en Trados Studio es exactamente el habitual, con la única diferencia de que en lugar de seleccionar una memoria de traducción seleccionaremos un motor de traducción automática (el que nos interese). El resto del proceso será el habitual.
Motor de traducción automática + Memoria de traducción humana
Una vez hayamos decidido qué motor de traducción automática usar y hayamos consultado disponibilidad a un poseditor (si así lo hemos decidido previamente), pasaremos a crear nuestro proyecto de posedición en Trados Studio.
Si ya tenemos el trabajo creado por haber usado “Compare MT”, simplemente iremos a “Configuración del proyecto” y en “Combinaciones de idiomas” eliminaremos el motor de traducción que no nos interese y añadiremos la memoria de traducción que sea y clicaremos en “Aceptar”:
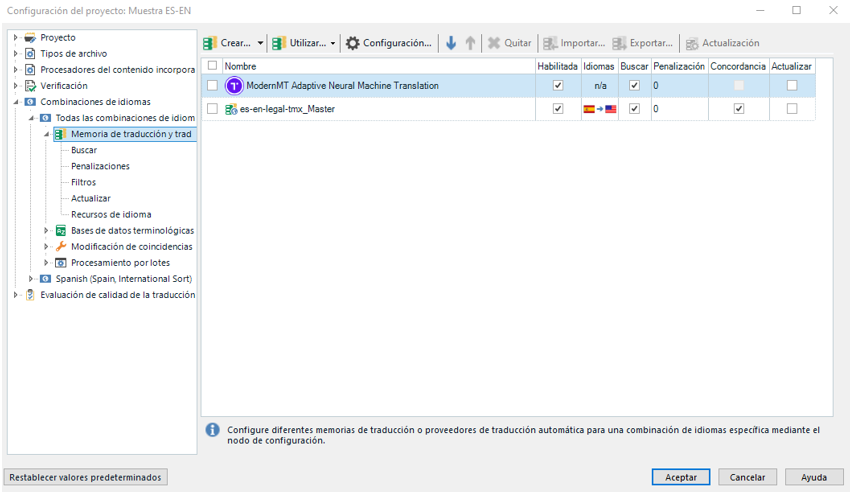
Los siguientes pasos serán muy importantes para configurar bien nuestro trabajo de posedición.
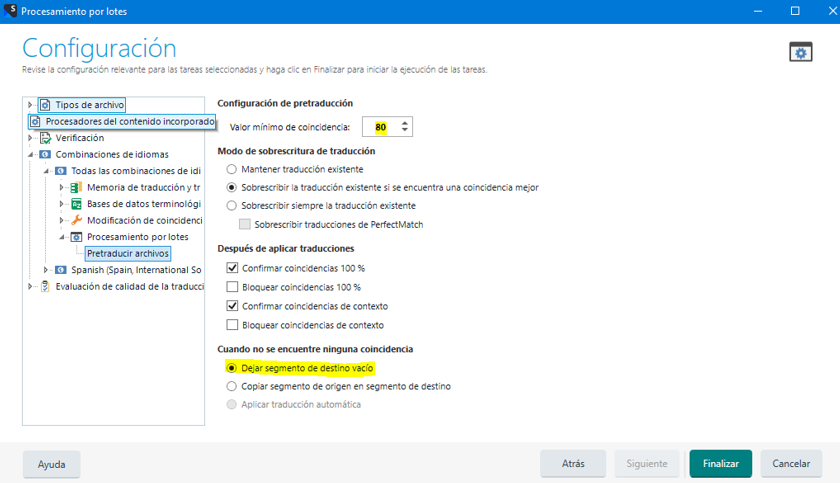
En primer lugar, pretraduciremos nuestro trabajo con la memoria de traducción (“Tareas por lotes” -> “Pretraducir archivos”). En la ventana de la configuración de la pretraducción, como valor mínimo de coincidencia elegiremos el 80% y “Dejar segmento de destino vacío” cuando no se encuentre ninguna coincidencia en la memoria de traducción:
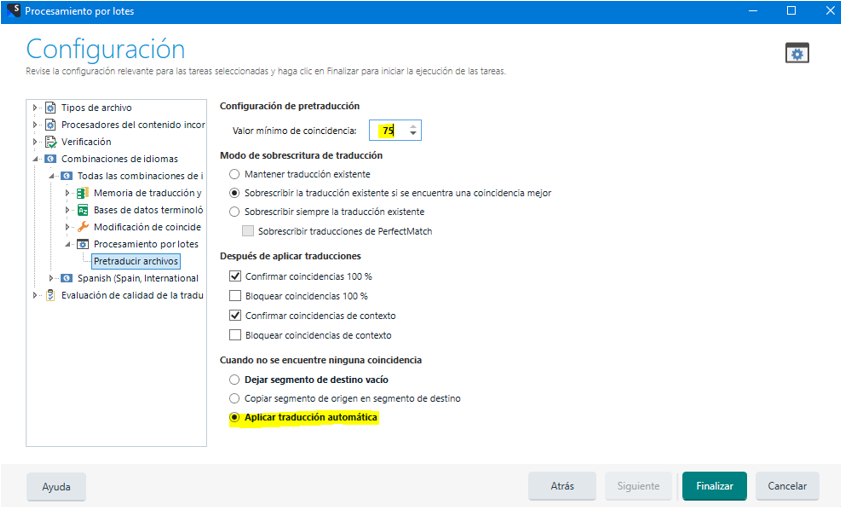
El siguiente paso será pretraducir nuestro trabajo con el motor de traducción automática deseado. Volvemos a “Tareas por lotes” -> “Pretraducir archivos”. En la ventana de la configuración de la pretraducción, como valor mínimo de coincidencia elegiremos el 75% y “Aplicar traducción automática” cuando no se encuentre ninguna coincidencia:
Haciendo la pretraducción en dos pasos y eligiendo los valores mínimos de coincidencia nos aseguramos de que todo el contenido que tenga una coincidencia mínima del 80% será de la memoria de traducción y, el resto, del motor de traducción automática.
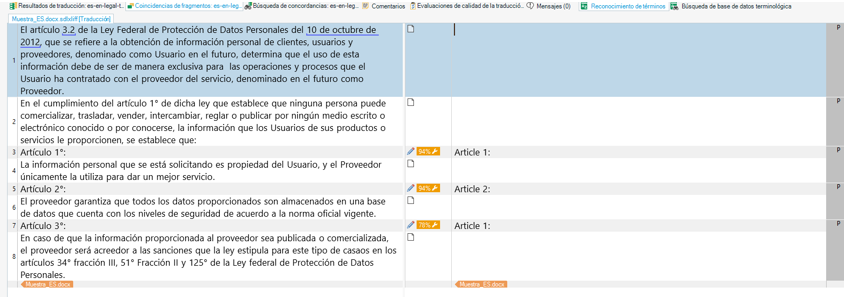
Así quedaría nuestro archivo después de la pretraducción:
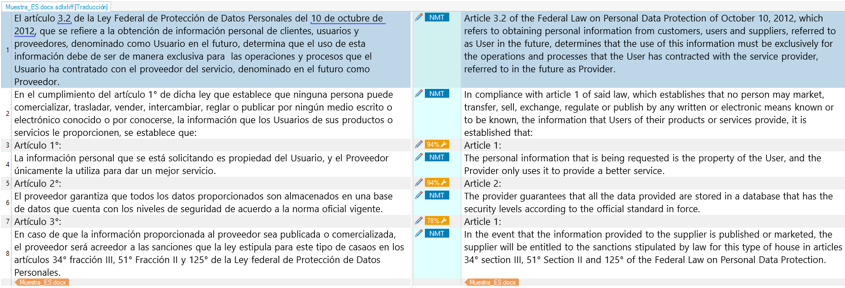
Ahora ya podemos pasar el trabajo al poseditor.
Motor de traducción automática + Memoria de traducción humana + Memoria de MTPE
Hay clientes que disponen tanto de memorias de traducción humana como memorias de traducción MTPE. Para poder aprovechar el máximo de todas ellas garantizando que los segmentos aplicados sean los de mayor calidad en cada momento se deberá seguir el siguiente proceso, que explica cómo crear y configurar un proyecto de Trados Studio donde se utilice una memoria humana de Trados Team (memoria humana) junto con una memoria de MTPE, también de Trados Team (memoria MTPE) y DeepL como motor de traducción automática (aunque el proceso sirve realmente también para cualquier motor de traducción).
El objetivo es configurar el proyecto de forma que durante la pretraducción Studio se decante en primer lugar por las coincidencias de la memoria humana en vez de las procedentes de la memoria MTPE, las cuales van después en orden de prioridad. En el caso de que no haya coincidencia en ninguna memoria, Studio utilizará DeepL para pretraducir esos segmentos.
Creación del proyecto
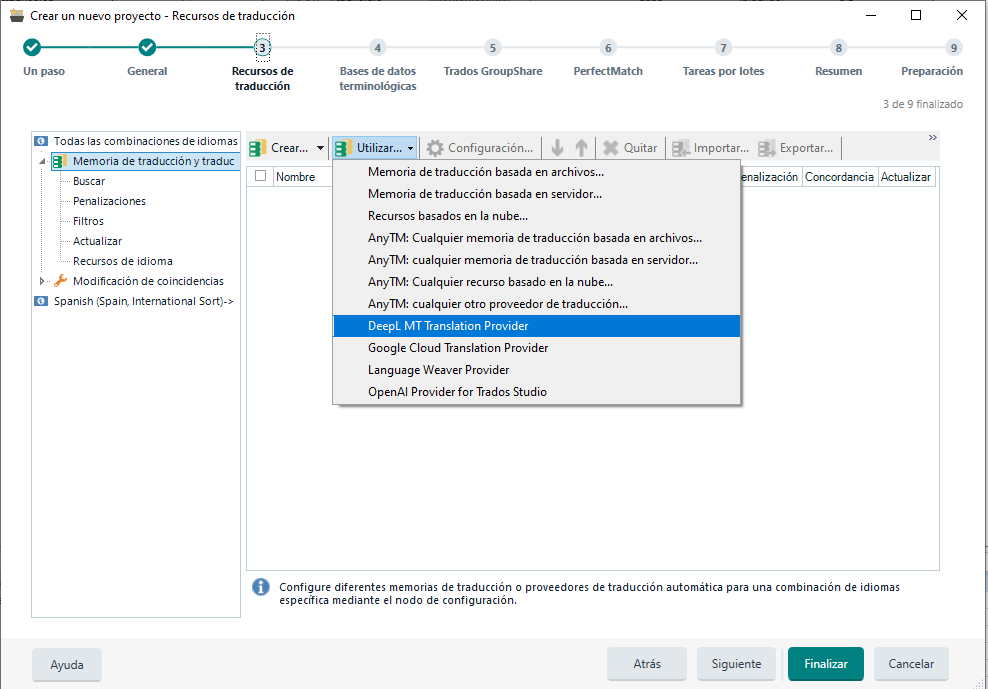
Una vez indicados los datos básicos del proyecto, tenemos que ir a Recursos de traducción y después pulsar en Utilizar > Recursos basados en la nube para añadir las memorias humana y MTPE correspondientes de una en una.
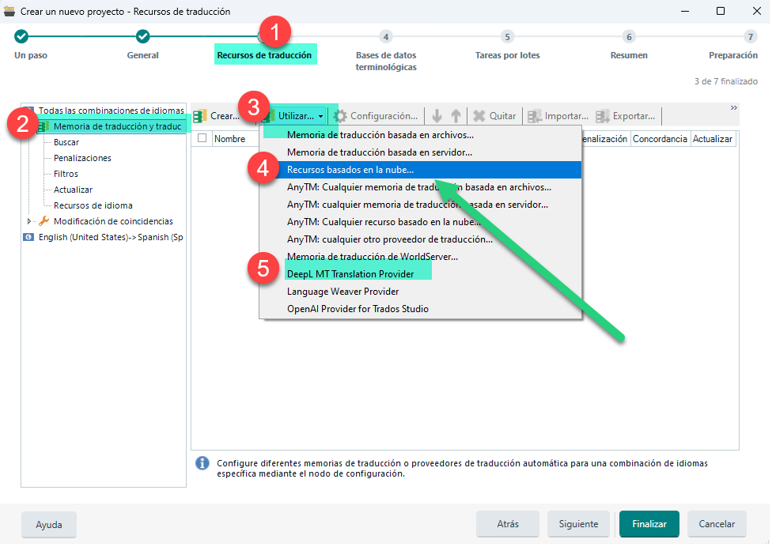
Después usaremos la opción DeepL MT Translation Provider para añadir DeepL como motor de traducción automática.
El siguiente paso es añadir una penalización del 15% a las coincidencias procedentes de la memoria MTPE.

De este modo, una coincidencia del 100 % que venga de la MTPE será tratada como un 85 % tras la penalización; una del 95 % será un 80 %, y así sucesivamente.
Asimismo, conviene desmarcar las casillas de Actualizar para evitar que las memorias sean alimentadas con traducciones temporales o no confirmadas.
Después cambiamos el porcentaje de coincidencia mínima al 75% para la pretraducción, de forma que todo lo que tenga una coincidencia del 75% o superior en cualquiera de las dos memorias quedará pretraducido.

En esta misma ventana marcamos la opción Aplicar traducción automática para que Studio use DeepL si no hay coincidencias iguales o superior al 75% en ninguna memoria.
Una vez hecha la configuración, terminamos de crear el proyecto de la forma habitual.
Resultados de la pretraducción
Con esta configuración, Studio aplica el siguiente orden durante la pretraducción:
- Coincidencias entre el 86 y el 100%: se aplica siempre la memoria humana, ya que, tras la penalización, en la MTPE no habrá nada inferior al 85%.
- Coincidencias entre el 75 y el 80%: se aplica la coincidencia de cualquiera de las dos memorias, con preferencia para el valor que sea más alto o para el que proceda de la memoria humana si hay una coincidencia con el mismo valor en cada memoria.
- Coincidencias inferiores al 75%: se usa traducción automática.
Coincidencias exactas
En aquellas situaciones donde haya coincidencias del 100% en la memoria humana, Studio usará esa coincidencia al pretraducir. Aunque haya una coincidencia exacta en la MTPE, ya no será del 100%, sino del 85%, pues se ha aplicado la penalización.
Si se da el caso de que ambas memorias tuvieran una coincidencia exacta con traducciones diferentes para el mismo segmento, Studio utilizaría la de la memoria humana, como se aprecia en este segmento.
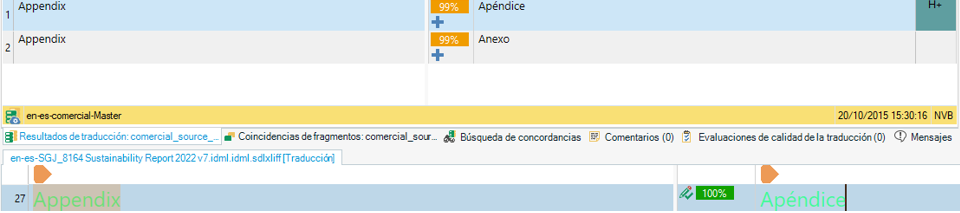
Este comportamiento es del deseable, ya que se debe dar prioridad a la memoria humana frente a la MTPE.
No obstante, vemos que en el cuadro de resultados de la memoria ambas constan como un 99%, ya que por defecto hay una penalización del 1 % para varias traducciones del mismo segmento. Esto puede ser confuso, pero se debe a que la pretraducción y la concordancia son dos funciones diferentes del programa que usan valores distintos y, como no se puede penalizar la concordancia, sigue apareciendo con un valor del 99% tras la penalización.
Debido a estas diferencias, puede ocurrir que un 85% de la memoria MTPE aparezca como una concordancia del 100% en la ventana de resultados de traducción, como se aprecia en esta imagen:
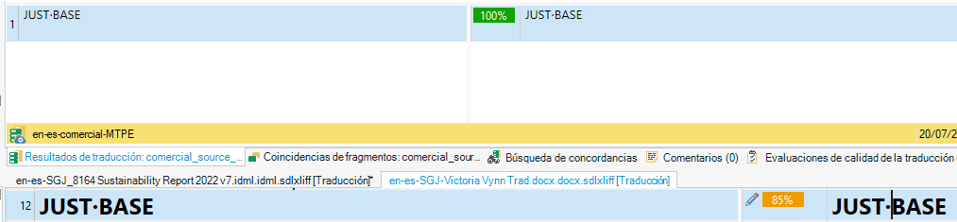
Coincidencias parciales de la memoria humana
En el caso de coincidencias parciales (85%-99%) procedentes de la memoria humana, Studio elige la sugerencia de esta memoria incluso si en la MPTE hay un 100% de concordancia, como se ve en este caso:

Como explicábamos antes, se debe a que los valores usados en la pretraducción y en la concordancia no son los mismos.
Este hecho provoca que se vea el aviso de destino diferente en la memoria de traducción, ya que el programa esperaría que se prefiriera el resultado de la MTPE por tener mejor porcentaje de concordancia. Este mensaje aparecerá en los casos similares a este.
Siempre se puede recuperar la sugerencia de la memoria MTPE si se considera que es mejor en el segmento en concreto, para lo cual se puede usar el atajo de teclado Ctrl + 1.
Coincidencias parciales de la memoria MTPE
La pretraducción usará los segmentos de la memoria MTPE durante la pretraducción solo cuando no haya ninguna coincidencia mejor en la memoria humana. Las coincidencias de la memoria MTPE siempre aparecerán como coincidencias parciales, ya que el valor más alto que pueden tener es del 85 % debido a la penalización.
En la siguiente captura vemos unos ejemplos de segmentos que tienen un 100% de coincidencia en la memoria MTPE, pero que ahora aparecen como 85% tras la penalización.

Traducción automática
Por último, siempre que no haya ninguna coincidencia en las memorias que sea igual o superior al 75%, Studio utilizará DeepL para pretraducir los segmentos:

Verificación y control de calidad de trabajos de posedición
Ver apartado 4 del Procedimiento PM003 – Procedimiento general Traducción Automática y Posedición (MTPE).
SDLXLIFF Compare
En primer lugar, debe instalarse el plugin para Trados Studio, que está disponible en la Página de descargas de la Okopedia, en “Plugins Trados Studio 2022”.
Abrimos el trabajo en cuestión que queramos verificar y, estando en la pestaña “Archivos”, vamos arriba a “Ver” y nos saldrá el plugin. Por defecto, también lo tenemos activo en la parte inferior de la pantalla:
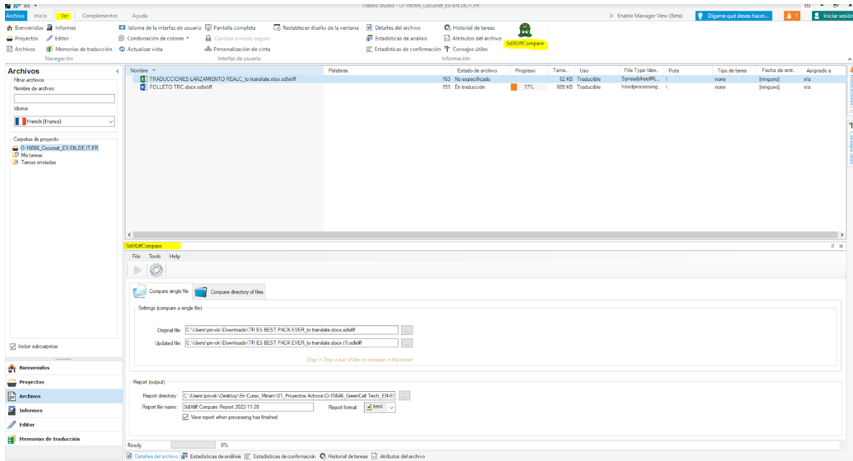
Para usarlo, clicamos en “Compare single file” (si solo hemos trabajado con un sdlxliff) o “Compare directory of files” (si tenemos varios archivos de trabajo).
Cargamos, por un lado, el archivo original que enviamos a poseditar y, por otro lado, el archivo que nos ha entregado el poseditor. Una vez cargados los archivos, en “Report” cambiaremos el report format a html.
El plugin nos generará un archivo comparado en ese formato:
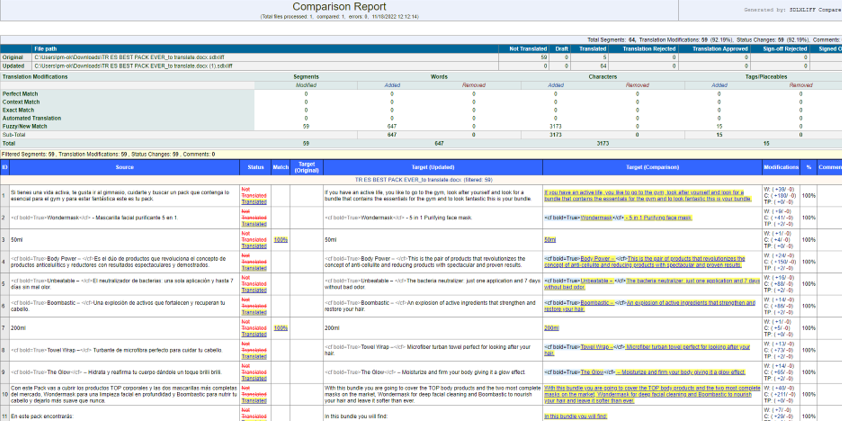
Si queremos consultar al poseditor algo en especial, podemos abrir el html que nos ha generado el plugin con Excel y tratarlo del mismo modo que los archivos que se generan con Xbench.
Solución de problemas
Si Trados te da error cuando intentas incluir algún motor o pretraducir algunos segmentos prueba a ir a la Appstore (que está arriba del todo a la izquierda, justo a la izquierda del botón de “Guardar”) y actualiza el plugin.
Si no hay ninguna actualización pendiente, desinstala el motor que te dé problemas, cierra Trados y borra estas carpetas y archivos de tu ordenador:
c:\Users\%username%\AppData\Roaming\Trados AppStore\[información del motor que te da problemas]\
c:\Users\%username%\AppData\Roaming\Trados\Trados Studio\18\Plugins\Packages\[información del motor que te da problemas].sdlplugin
c:\Users\%username%\AppData\Roaming\Trados\Trados Studio\18\Plugins\Unpacked\[información del motor que te da problemas]\
Luego, descarga el plugin desde la Appstore e instálalo de nuevo. Tras reiniciar Trados, ya debería funcionar.
Si no lo hace, ponte en contacto con el técnico especialista.